DAP4: Data Model: Difference between revisions
(Created page with " = Definitions = ;Grid : One or more N-dimensional arrays of values bound to 1 to N coordinate variables. In DAP2 the Grid type was limited to one-dimensional coordinate variabl...") |
No edit summary |
||
| (123 intermediate revisions by 2 users not shown) | |||
| Line 1: | Line 1: | ||
[[Category:Development|Development]] [[Category:DAP4|DAP4]] | |||
<font size="+1" color="red">This is an old document that captures the starting point of the OPULS design work. It's out of date and should be referenced only as a baseline for the work.</font> | |||
[[OPULS_Development | <-- back to OPULS Development]] | |||
Author: [[User:Jimg|Jimg]] | |||
: | |||
; | == Definitions == | ||
: A data type that cannot be divided using the operators provided by DAP4. The set of | |||
;Cardinal Type | |||
: A data type that cannot be divided using the operators provided by DAP4. The set of Cardinal types are: Byte, Int16, Int32, Int64, their unsigned companions, Float32, Float64, String, URL. Enum (Enumerations) and Opaque. | |||
;Constructor Type | ;Constructor Type | ||
: A data type used to build new structures for representing information. Constructor types gain flexibility by allowing instances of themselves to be elements in a constructed type (i.e., they support recursive definitions). | : A data type used to build new structures for representing information. Constructor types gain flexibility by allowing instances of themselves to be elements in a constructed type (i.e., they support recursive definitions).<font color="red">I think this should be "nested definitions" not "recursive definitions" [[User:Ndp|ndp]] 11:28, 16 February 2012 (PST)</font> The ''Structure'', ''Sequence'' and ''Grid'' are the Constructor types in DAP. | ||
;Aggregator Type | ;Aggregator Type | ||
: Arrays and type-homogeneous lists are aggregator types. | : Arrays and type-homogeneous lists are aggregator types. DAP does not contain a List data type since lists can be represented by ''Sequences'' with a single element. | ||
;Variable-size Type | ;Variable-size Type | ||
: A data type that does not define a fixed number of bits/bytes for its network representation. Examples of these types are Strings, Opaques and Sequences. Note that an Array or Structure containing instances of Opaque defines a variable-size type | : A data type that does not define a fixed number of bits/bytes for its network representation. Examples of these types are Strings, Opaques and Sequences. Note that an Array or Structure containing instances of Opaque defines a variable-size type while an Array or Structure that contains only, say, Int32 variables, defines a Fixed-size Type. | ||
;Fixed-size Type | ;Fixed-size Type | ||
: A data type with a fixed size regardless of the value(s) contained. | : A data type with a fixed size regardless of the value(s) contained. | ||
;Dimension | ;Dimension | ||
| Line 30: | Line 30: | ||
;Independent Variable | ;Independent Variable | ||
: A variable included in a data source which is manipulated during measurement or calculation. For example, a ship collecting information about sea temperature might conduct measurements at different latitude and longitudes - the variables used to hold those latitude and longitude values can be described as ''independent variables.'' The term has its origin in Mathematics and Statistics, each of which have subtly different definitions, but in the context of a data source the independent variables are often | : A variable included in a data source which is manipulated during measurement or calculation. For example, a ship collecting information about sea temperature might conduct measurements at different latitude and longitudes - the variables used to hold those latitude and longitude values can be described as ''independent variables.'' The term has its origin in Mathematics and Statistics, each of which have subtly different definitions, but in the context of a data source the independent variables are often ones that might be encoded as attributes and not variables except for the fact that the values of an independent variable are often larger in volume (KB to MB) and users of the data often need to select a subset of the values, an operation that is often not supported for attributes. | ||
;Coordinate Variable | |||
: A Coordinate Variable is the binding of a Shared Dimension to a data type so that the values of an independent variable may be stored in a data source and their relation to a dependent variable made explicit. The Grid data type is used by DAP4 to define coordinate variables, which it names ''Map''s. | |||
;Dependent Variable | ;Dependent Variable | ||
: A variable included in a data source which is measured or calculated as a function of independent variables. For example, if a data source held demographic information about cities' populations and median income levels, the data about income levels would be a dependent variable. As with the term ''independent variable,'' this term has its origin in Mathematics and statistics. | : A variable included in a data source which is measured or calculated as a function of independent variables. For example, if a data source held demographic information about cities' populations and median income levels, the data about income levels would be a dependent variable. As with the term ''independent variable,'' this term has its origin in Mathematics and statistics. | ||
= Data Model = | ;Fully Qualified Name (FQN) | ||
: Every object in a DAP4 Dataset has a Fully Qualified Name. These names follow the common conventions of lexically-scoped identifiers. To write FQNs, the component names are listed, left to right, corresponding to a traversal of the scopes from outermost to innermost, using dots (.) to separate names associated with lexical scopes. Cases where dots are used in names are accommodated by allowing the names to be quoted and quotes to be escaped using a backslash (\). The (unlikely) sequence "\'" can be represented using "\\'". That is, the backslash can itself be escaped although that is only needed if it is a literal and immediately precedes a literal single quote ('). | |||
== Data Model == | |||
[[Image:DAP 2 DM UML.png|400px|DAP 2 Conceptual Data Model]][[Image:DAP 4 DM UML.png|600px|DAP 4 Conceptual Data Model]] | [[Image:DAP 2 DM UML.png|400px|DAP 2 Conceptual Data Model]][[Image:DAP 4 DM UML.png|600px|DAP 4 Conceptual Data Model]] | ||
DAP is evolving to meet the increasing complexity of data sources and the improving capabilities of analysis software to act as clients for various online data sources. Part of this evolution is to adopt the [http://www.unidata.ucar.edu/software/netcdf-java/CDM/index.html Common Data Model] that has been developed by Unidata. Other changes are the introduction of new data types and the expansion of capabilities of the widely used 'Grid' type. The Grid type in DAP4 will allow for N-dimensional 'Maps,' multiple 'Array' components and Array components that do not use all of the Maps. Finally, some types like Array of Grid and Array of Sequence have been eliminated because they lack real use-cases and are hard to implement. By eliminating them we hope client authors will focus on complete implementations of the existing types | DAP is evolving to meet the increasing complexity of data sources and the improving capabilities of analysis software to act as clients for various online data sources. Part of this evolution is to adopt the [http://www.unidata.ucar.edu/software/netcdf-java/CDM/index.html Common Data Model] that has been developed by Unidata. Other changes are the introduction of new data types and the expansion of capabilities of the widely used 'Grid' type. The Grid type in DAP4 will allow for N-dimensional 'Maps,' multiple 'Array' components and Array components that do not use all of the Maps. Finally, some types like Array of Grid and Array of Sequence have been eliminated because they lack real use-cases and are hard to implement. By eliminating them we hope client authors will focus on complete implementations of the existing types. | ||
The DAP 2 and DAP 4 data models are shown to the above. | The DAP 2 and DAP 4 logical data models are shown to the above, although some details, are skipped. The UML constraint ''shape'' indicates if something is an array - shape == 0 means the variable is a scalar while shape > 0 means it has one or more ''dimensions''). | ||
High resolution version of the [http://docs.opendap.org/images/9/98/DAP_2_DM_UML.png DAP 2 Data Model] | High resolution version of the [http://docs.opendap.org/images/9/98/DAP_2_DM_UML.png DAP 2 Data Model] | ||
High resolution version of the [http://docs.opendap.org/images/7/7e/DAP_4_DM_UML.png DAP 4 Data Model] | High resolution version of the [http://docs.opendap.org/images/7/7e/DAP_4_DM_UML.png DAP 4 Data Model] | ||
= | === Dataset === | ||
== | |||
In DAP4, the ''Dataset'' object forms the root of the representation of a dataset. In DAP2, this task was split between two different objects, the DDS and DAS, which were also the names of objects used in many implementations. For DAP4, implementations could use the name ''Dataset''. All of the information contained in the data model will be encoded in a 'Dataset response'. In addition, some bookkeeping information might be added to the ''Dataset'' response by the server. For a full discussion of the use of the Dataset object in the DAP4 responses [http://docs.opendap.org/index.php/DAP4:_Responses#Dataset_Response please see the DAP4: Responses page.] | |||
== Data Types == | |||
DAP 4 will have a small increase in supported data types. All of the DAP 2 data types describe in [http://www.esdswg.org/spg/rfc/ese-rfc-004 ESE RFC 004.11] will be supported with the following exceptions: | |||
# ''Byte'' will now indicate a ''signed'' 8-bit integer data type (so that UByte can be used to name an unsigned 8-bit integer in keeping with the pattern developed for the ''*Int??'' types). | |||
# Arrays of Grid and Sequence are explicitly excluded from DAP4. | |||
# The ''Grid'' type will have some important limitations removed. | |||
# The ''String'' type will hold character strings that comply with UTF-8. | |||
# The ''URL'' type will comply with the forthcoming IRI RFC. | |||
DAP4 will contain new datatypes that support 64-bit integers, an ''Opaque'' type that can be used for data objects like JPEG images, a ''Group'' type that can be used to build logical collections as in NetCDF4 or HDF5 (with some limitations over HDF5's definition of Group). In addition, DAP 4 will provide for shared ''Dimensions'' and type definitions. | |||
The | === New Datatypes === | ||
==== Groups ==== | |||
The ''Dataset'' object must contain one or more ''Group'' objects. Like ''Shared Dimensions and unlike the other types, ''Group'' provides a way to form logical associations of variables. Unlike ''Structure'', it cannot itself be used as a component in a constructor type. For example, it is not possible to have an ''Array of Group'' while it is certainly possible to have an ''Array of Structure''. | |||
Group characteristics: | Group characteristics: | ||
# The Group object is similar to the notion of a namespace in a programming languages. | |||
# Each Group declares a new lexical scope for names. | |||
# A Group can contain any object(s), including other Groups. | |||
# All Groups must be named. | |||
# All Groups may have shared ''Dimensions'', which are limited in scope to the enclosing Group. | |||
# All Groups may have DAP Attributes. | |||
# At least one Group must be defined; if a dataset lacks a Group declaration, a Group called ''root'' will be defined and all of its variables will be added to that Group. | |||
# A Group cannot be used with a constructor type. | |||
# NB: This definition does not completely subsume the HDF5 Group type but is equivalent to the netCDF 4 version of it. This Group object defines a series of relationships that are purely hierarchical and not a generalized graph (as is the case with the HDF5 Group data model component). Note however, that the URL/IRI type can be used in one Group to reference variables and ''Dimensions'' (but not other Groups) defined in another Group. | |||
=== Shared Dimensions === | ==== Shared Dimensions ==== | ||
Shared | ''Shared Dimensions'' will be added to DAP in the ''dimensions'' section of ''Grid'' objects. Each shared dimension will consist of a name and a size. | ||
Characteristics of Shared Dimensions: | |||
# Shared Dimensions are not associated with a data type. | |||
# Shared Dimensions do not have DAP attributes. | |||
# Every Shared Dimension has both a name and a size. | |||
# Shared Dimensions are scoped to the Grid that contains them. | |||
# Shared Dimensions are used to define a Map in a Grid. | |||
# Shared Dimensions bind indices in a Map to indices in an Array, forming a linkage between the Array and Map values. | |||
==== How Group and Dimension differ from other parts of the data model ==== | |||
Both ''Group'' and ''Dimension'' are used to provide syntactic or structural metadata about a dataset. They do not contain data values themselves. In many cases these objects will not be explicitly represented in the original dataset. Instead, their existence and value(s) will be inferred based on various standards and conventions. The other elements of the data model are used to house data values or semantic metadata read from the dataset (or, in the latter case) synthesized from the values and standards/conventions that the dataset is known to follow. | |||
=== Opaque === | ==== Opaque ==== | ||
The Opaque type is use to hold objects like JPEG images and other Binary Large Object (BLOB) data that have significant internal structure which might be understood by clients (e.g., an image display program) but that would be very cumbersome to describe using DAP's built-in types. Defining a variable of type 'Opaque' does not communicate any information about its content, although an attribute could be used to do that. | |||
The Opaque type is use to hold objects like JPEG images and other BLOB | |||
# A variable of type Opaque is treated as a Byte array for the purposes of transmission. This means there is no attempt to re-order four-byte words to or from network byte order and that the block of bytes is extended to fill a four-byte boundary | # A variable of type Opaque is treated as a Byte array for the purposes of transmission. This means there is no attempt to re-order four-byte words to or from network byte order and that the block of bytes is extended to fill a four-byte boundary | ||
# The size of an Opaque variable is unknown until the data are read/received | # The size of an Opaque variable is unknown until the data are read/received | ||
# The Opaque type | # The Opaque type is a Cardinal Type, which might seem odd because instances of Opaque can be of different sizes. However, comparing similar aspects of Opaque and String indicate that they are Cardinal Types after all. | ||
# NB: Cardinal Types can appear in Group, Array, Structure, Grid and Sequence parts of the data model. | |||
==== 64-bit Integers ==== | |||
Signed and Unsigned 64-bit integers. | Signed and Unsigned 64-bit integers. | ||
=== Enumeration === | ==== Enumeration ==== | ||
When a data source has a variable of type 'Enumeration' a DAP 4 server MUST represent that variable using a ''integer type'', up to an including a 64-bit unsigned integer. However, in practice, these should use ''Byte'' variables when transporting the values unless an enumeration contains values too large for that type. This is true because DAP4 will use XDR to encode responses and thus Arrays of Enumerations will encode directly to single byes. If we use other types, like Int16, then they will expand to be 32-bit integers. On the other hand, a single Enumeration will expand to a 32-bit integer for encoding by XDR, but that cost is fairly small. | |||
==== Variable Length Arrays ==== | |||
Any type that can be an array can have one dimension marked as ''varying'' instead of being a fixed size, so long as that dimension is the ''rightmost'' dimension. | |||
A ''Coordinate'' may not have a dimension that varies; nor may a ''SharedDimension'' be varying. | |||
=== Changes to | === Changes to Existing Types === | ||
==== Changes to index sizes ==== | |||
DAP4 will support Arrays and Grids with 64-bit unsigned indexes. | DAP4 will support Arrays and Grids with 64-bit unsigned indexes. | ||
=== | ==== Signed Bytes ==== | ||
''Byte'' will be a signed 8-bit integer and ''UByte'' will be an unsigned 8-bit integer. NB: In DAP2, the ''Byte'' data type is defined as an unsigned 8-bit integer and there is no signed 8-bit integer type. | |||
==== | ==== Changes to the String Type ==== | ||
A String is a sequence of characters encoded using UTF-8. Servers MUST translate from local encoding to UTF-8 and client must translate received string data from UTF-8 to any local representation if is not UTF-8. In DAP2, strings were simple C-sytle strings using only ASCII characters. | |||
==== Changes in the Definition of Grid ==== | |||
In DAP2, the concept of a ''grid'' was bound to a datatype that defined its own lexical scope as well as a specific set of operations. In DAP4, the lexical scope has been replaced by a ''Grid'' type that 'specializes' the Array type by adding explicit references to one or more ''Map'' (aka ''coordinate variable'') variables such that several Grid variables can share one set of Maps. Furthermore, unlike DAP2 the Maps are no longer limited to a rank of one. A Map is also a specialization of an Array. | |||
* General information about Grid: | |||
# A Grid variable is a relational type. | |||
# Dimensions provide the binding between Grid (dependent) and Map (independent) values. The Map value at (i<sub>0</sub>, i<sub>1</sub>, ..., i<sub>n</sub>) is bound to the Grid value at the same indicial coordinates when both the Grid and Map use the same shared dimensions for those indices. | |||
* Grids: | |||
# Each Grid variable is an ''Array''-type variable (what is often termed a ''dependent variable'' in scientific literature) that has been specialized to include explicit references to one or more Map variables. | |||
# An Grid of rank N may have 1 ... N Maps. | |||
# There is an explicit binding between the Maps and the dimensions of the Grid. | |||
# For an Grid of rank N, all of the Maps referenced by its dimensions must be of rank M <= N. | |||
# Grids may have attributes. | |||
* Maps: | |||
# Maps (often called ''independent variables'') have one or more dimensions. | |||
# Map variables are a restricted class of arrays; only Maps of Byte, ..., Enum are allowed. Maps are a specialization of Array. | |||
# Maps are required to use shared Dimension objects for all of their dimensions. | |||
# Maps may have DAP Attributes. | |||
===== Examples: ===== | |||
====== A fairly complex Grid example ====== | |||
This example has four Grids and three Coordinate objects. | |||
How the Coordinates and Grids relate: For any (x,y) value of SST, the latitude and longitude that corresponds to that point can be found from the latitude and longitude Coordinates using those same indices. The Grid indicates that by explicitly sharing the x and y dimensions with those Coordinates using the ''dimension'' element's ''ref'' attributes and binding the Coordinate to that dimension using the ''map'' attribute. For the AirT array, the lat and lon of any (x,y,z) point can be found using (x,y) and the altitude of any point (x,y,z) can be found using the (x,y,z) value of the altitude Coordinate. Again, the shared dimensions provide explicit bindings between the Grid and Coordinate values. Two other examples are shown; no example of a Grid with simple vector coordinates is shown. | |||
==== | <font size="2"> | ||
<source lang="xml"> | |||
<Dimension name="x" size="1024"/> | |||
<Dimension name="y" size="1024"/> | |||
<Dimension name="z" size="12"/> | |||
< | <!-- The dimensions of a Coordinate MUST be SharedDimensions --> | ||
< | <Map name="longitude" type="Float32"> | ||
<dimension ref="x"/> | |||
<dimension | <dimension ref="y"/> | ||
</Map> | |||
<Map name="latitude" type="Float32"> | |||
<dimension ref="x"/> | |||
<dimension ref="y"/> | |||
</Map> | |||
<Map name="altitude" type="Int32"> | |||
<Attribute name="unit" type="String"><value>ft</value></Attribute> | |||
<dimension ref="x"/> | |||
<dimension ref="y"/> | |||
<dimension ref="z"/> | |||
</Map> | |||
<!-- These are the grids... --> | |||
<Byte name="SST"> | |||
<dimension ref="x"/> | |||
<dimension ref="y"/> | |||
<map name="latitude"/> | |||
<map name="longitude"/> | |||
</Byte> | |||
</ | |||
==== | <!-- A mixture of two and three-dimensional coordinates --> | ||
<Int16 name="AirT"> | |||
<dimension ref="x"/> | |||
<dimension ref="y"/> | |||
<dimension ref="z"/> | |||
<map name="latitude"/> | |||
<map name="longitude"/> | |||
<map name="altitude"/> | |||
</Int16> | |||
< | <!-- ...some dimensions lack coordinates --> | ||
< | <Float64 name="intercomparison_result"> | ||
<dimension | <dimension ref="x"/> | ||
<dimension | <dimension ref="y"/> | ||
<dimension ref="z"/> | |||
<map name="altitude"/> | |||
</Float64> | |||
<!-- ...and in this case the highest dimension coordinate cannot be used to determine the | |||
grid/array rank. --> | |||
<UByte name="model_temperature"> | |||
<dimension ref="x"/> | |||
<dimension ref="y"/> | |||
<dimension ref="z"/> | |||
<dimension name="run_number" size="7" /> | |||
<map name="latitude"/> | |||
<map name="longitude"/> | |||
<map name="altitude"/> | |||
</UByte> | |||
</source> | |||
</font> | |||
< | |||
<dimension | |||
<dimension | |||
< | |||
<dimension name=" | |||
=== Types not Included === | |||
Discussed in this section are types that are present in some other systems (e.g., ASN 1.1) but that are not explicitly included in DAP 4. For all of these, the information they would encode should be included using attributes. This makes the information available in a way that clients can access if they choose and which people can easily understand without loading up the data model with complexity or optional features. While understanding and reading these attributes is optional for clients, it is required behaviour for conforming servers to encode this information as described here. | Discussed in this section are types that are present in some other systems (e.g., ASN 1.1) but that are not explicitly included in DAP 4. For all of these, the information they would encode should be included using attributes. This makes the information available in a way that clients can access if they choose and which people can easily understand without loading up the data model with complexity or optional features. While understanding and reading these attributes is optional for clients, it is required behaviour for conforming servers to encode this information as described here. | ||
=== Date/Time === | ==== Date/Time ==== | ||
When a data source has a variable of type ''Date'', ''Time'' or a type that combines those two, a DAP 4 server MUST represent that variable using the String type and include an attribute for that variable named ''DAP4_Date'', ''DAP4_Time'' or ''DAP4_DateTime''. The type of the attribute must be String and it must have only one value and that value must indicate how to interpret the date/time value(s) of the variable. As a special case, if the value is ''ISO-8601'' then a client program can assume that the ISO 8601 standard for representation of dates and times is used. | When a data source has a variable of type ''Date'', ''Time'' or a type that combines those two, a DAP 4 server MUST represent that variable using the String type and include an attribute for that variable named ''DAP4_Date'', ''DAP4_Time'' or ''DAP4_DateTime''. The type of the attribute must be String and it must have only one value and that value must indicate how to interpret the date/time value(s) of the variable. As a special case, if the value is ''ISO-8601'' then a client program can assume that the ISO 8601 standard for representation of dates and times is used. | ||
=== Type definitions === | ==== Type definitions ==== | ||
Both HDF5 and NetCDF4 include this as a feature; it is of considerable value for an API that will be used to write data because it provides a way to make a template file with only the data type defined and then have people instantiate those types, resulting in much uniformity. For a data access system, which is read-only, there's less benefit and clients have to be more sophisticated. | |||
Both HDF5 and NetCDF4 include this as a feature; it is of considerable value for an API that will be used to write data because it provides a way to make a template file with only the data type defined and then have people instantiate those types, resulting in much uniformity. For a data access system, which is read-only, there's | |||
DAP4 will not support type definitions (except for Enumerations and SharedDimensions). There is a down side to not supporting the feature, however, and that is that it becomes harder to faithfully represent what's in a data set. | |||
Potential solution: | |||
# Include type definitions in an attribute section - Dataset or Group scope - and then in every Structure that represents a collection of variables with a typedef in the source, include an attribute that names the typedef. This solution frees clients from having to interpret the typedef but savvy clients can reconstruct the original information if needed. | |||
==== | == Attributes == | ||
In DAP4, Attributes (not to be confused with XML attributes) are tuples with four values: | |||
* Name | |||
* Type | |||
* Vector of values | |||
* Namespace | |||
This differs slightly from DAP2 Attributes because the ''namespace'' feature has been added, but clients can choose to ignore it. The intent of including the namespace information is to simplify interactions with semantic web applications where certain formats or standards have formal definitions of attributes (e.g., CF-1.x). | |||
A second difference is that DAP4 explicitly realizes that an attribute with one value is really an attribute whose value is a one-element vector. | |||
=== Allowed attribute types === | |||
The following types are allowed for Attributes: | |||
* All of the Cardinal types except Opaque. | |||
* Arbitrary XML | |||
* Containers (i.e., Structures, but without the capability to be arrays) | |||
As with the String variable type, String Attributes use UTF-8 encoding. | |||
=== Arbitrary XML content === | |||
By supporting an explicit type to hold 'arbitrary XML' markup, DAP4 provides a way for the protocol to transport information encoded in XML along with the attributes read from the dataset itself. This has proved very useful in work with semantic web software. | |||
In an XML representation of DAP4, the name is optional, the XML element is ''<OtherXML/>'' and there are no ''<value/>'' elements because the 'other xml' appears as the content of the ''<OtherXML/>'' element. The value of the attribute must be valid XML and must be distinct from the XML markup used to encode elements of the DAP4 data model (i.e., in a practical sense, the OtherXML must be in a namespace other than DAP4). | |||
== Names == | |||
Every object in a DAP4 Dataset has a Fully Qualified Name. These names follow the common conventions of lexically-scoped identifiers. To write FQNs, the component names are listed, left to right, corresponding to a traversal of the scopes from outermost to innermost, using dots (.) to separate names associated with lexical scopes. Cases where dots are used in names are accommodated by allowing the names to be quoted and quotes to be escaped using a backslash (\). The (unlikely) sequence "\'" can be represented using "\\'". That is, the backslash can itself be escaped although that is only needed if it is a literal and immediately precedes a literal single quote ('). | |||
: | === Objects with FQNs === | ||
Each of these Types or Objects has a FQN and some also define a lexical scope: | |||
* Group: A group defines a lexical scope | |||
* SharedDimension | |||
* Map (A Map is a restricted type of an Array) | |||
* Cardinal types | |||
* Arrays | |||
* Types that define lexical scopes: | |||
** Structure | |||
** Sequence | |||
** Grid | |||
==== | == Constraint Expressions == | ||
In DAP4, Constraint Expressions define the set of operations that the server must support for each data type. These operations are how subsetting and sampling of data are specified and provide the mechanism by which clients indicate which data they want. | |||
The Constraint Expression is encoded as a string and is sent to the server as part of a data request. It is described in the section on Requests and Responses. | |||
Each Constraint Expression (CE) consists of two parts: | |||
;Projection: Zero or more projection clauses specify what variables are to be included in the response | |||
;Selection: Zero or more selection clauses are each evaluated for truth and used to determine which values are to be included for the variables named in the projection. The value (true or false) of the selection part is the logical AND of the clauses. Evaluators can stop processing the clauses when the first false value is found. There is no logical OR operation. | |||
The Projection component of the CE is used to: | |||
* Chose which variables are to be retrieved from the dataset | |||
* Which parts of Arrays are to be retrieved, using a 'slicing' concept similar to Python or netCDF3/4 or HDF4/5. | |||
* Which fields of compound types are to be retrieved, using fully qualified names for the fields. | |||
* Call functions that return values | |||
* List several variables and/or functions to retrieve in one operation. | |||
The Selection component of the CE is used to limit the data returned ''by value'': | |||
* For a Cardinal type that is a member of a Sequence, return only those elements of the Sequence that satisfy a set of relational clauses | |||
* For Arrays, return only those elements that satisfy a set of relational clauses. The result of this is a Sequence with N+1 columns for a rank N array; one column for each dimension plus one for the value. | |||
* Functions can be used in place of relational operators | |||
=== Differences between DAP2 and DAP4 Constraint Expressions === | |||
# DAP4 does not support applying array slicing to a Grid. Of course, fields/components of the Grid can be part of the Projection and, since those are arrays, the slicing operator can be used on them. | |||
# An Array may be subset by value using the 'selection' in DAP4 | |||
# Functions may appear in both the projection and selection parts of the CE. | |||
## ''Projection functions'' compute values that are returned | |||
## ''Selection functions'' evaluate to true or false | |||
## DAP2 supported a third kind of function that was used to add 'synthesized' variables to a dataset; those are not included in DAP4 since other techniques can be used to add new variables to a dataset. | |||
== | == Errors == | ||
An unsuccessful DAP4 request will cause the server to return a DAP4 error response. The error response may be returned in lieu of the Dataset response, or as part of the Data response. The XML used in the Error response is detailed in the DAP4 schema. | |||
DAP4 Data responses are chunked and DAP4 errors always appear in an error chunk. As the client processes a DAP4 Data response it reads the (fixed length) chunk header prior to reading the chunk. The chunk header will signal to the client that the following chunk contains a DAP4 error object. This enables the client to transition to an error processing state prior to ingesting the error. This is true even when the response contains only an error chunk. | |||
There are | There are 4 types of DAP4 errors. | ||
= | === Internal Error === | ||
The error is internal to the Server. Some examples of this are: | |||
* a programming bug/issue. | |||
* out of memory | |||
* disk fail | |||
=== User Syntax Error === | |||
The request contains a syntax error in the selection or the projection clause of the constraint expression. The server should return a message in the error object that explains where in the constraint expression the problem was detected. | |||
=== Forbidden Error === | |||
The requestor is not allowed to access the resource. | |||
<font color="green">I'm starting to think that a Forbidden Error doesn't belong in the DAP4 spec. I think it's the case that in a regular client/server interaction we would expect the authentication/authorization to be handled outside of the DAP4 protocol. If the server is having troubles accessing a resource because of some local/internal issue (like the service is running as a user that isn't allowed to read the resource) then that is starting to sound to me more like an Internal Error. Thoughts?? [[User:Ndp|ndp]] 12:55, 21 March 2012 (PDT)</font> | |||
== | === Not Found Error === | ||
The requested resource cannot be found. | |||
Latest revision as of 19:14, 31 August 2012
This is an old document that captures the starting point of the OPULS design work. It's out of date and should be referenced only as a baseline for the work.
Author: Jimg
Definitions
- Cardinal Type
- A data type that cannot be divided using the operators provided by DAP4. The set of Cardinal types are: Byte, Int16, Int32, Int64, their unsigned companions, Float32, Float64, String, URL. Enum (Enumerations) and Opaque.
- Constructor Type
- A data type used to build new structures for representing information. Constructor types gain flexibility by allowing instances of themselves to be elements in a constructed type (i.e., they support recursive definitions).I think this should be "nested definitions" not "recursive definitions" ndp 11:28, 16 February 2012 (PST) The Structure, Sequence and Grid are the Constructor types in DAP.
- Aggregator Type
- Arrays and type-homogeneous lists are aggregator types. DAP does not contain a List data type since lists can be represented by Sequences with a single element.
- Variable-size Type
- A data type that does not define a fixed number of bits/bytes for its network representation. Examples of these types are Strings, Opaques and Sequences. Note that an Array or Structure containing instances of Opaque defines a variable-size type while an Array or Structure that contains only, say, Int32 variables, defines a Fixed-size Type.
- Fixed-size Type
- A data type with a fixed size regardless of the value(s) contained.
- Dimension
- The term dimension is used in some places as a short form for Shared Dimension, defined below.
- Shared Dimension
- A Shared Dimension is the binding of a name to a integer. The name can then be used in place of the integer to indicate the extent of a variable with one or more dimensions. Using a Shared Dimension to describe the extent of two or more array variables describes the way that parts of the variables are related.
- Independent Variable
- A variable included in a data source which is manipulated during measurement or calculation. For example, a ship collecting information about sea temperature might conduct measurements at different latitude and longitudes - the variables used to hold those latitude and longitude values can be described as independent variables. The term has its origin in Mathematics and Statistics, each of which have subtly different definitions, but in the context of a data source the independent variables are often ones that might be encoded as attributes and not variables except for the fact that the values of an independent variable are often larger in volume (KB to MB) and users of the data often need to select a subset of the values, an operation that is often not supported for attributes.
- Coordinate Variable
- A Coordinate Variable is the binding of a Shared Dimension to a data type so that the values of an independent variable may be stored in a data source and their relation to a dependent variable made explicit. The Grid data type is used by DAP4 to define coordinate variables, which it names Maps.
- Dependent Variable
- A variable included in a data source which is measured or calculated as a function of independent variables. For example, if a data source held demographic information about cities' populations and median income levels, the data about income levels would be a dependent variable. As with the term independent variable, this term has its origin in Mathematics and statistics.
- Fully Qualified Name (FQN)
- Every object in a DAP4 Dataset has a Fully Qualified Name. These names follow the common conventions of lexically-scoped identifiers. To write FQNs, the component names are listed, left to right, corresponding to a traversal of the scopes from outermost to innermost, using dots (.) to separate names associated with lexical scopes. Cases where dots are used in names are accommodated by allowing the names to be quoted and quotes to be escaped using a backslash (\). The (unlikely) sequence "\'" can be represented using "\\'". That is, the backslash can itself be escaped although that is only needed if it is a literal and immediately precedes a literal single quote (').
Data Model


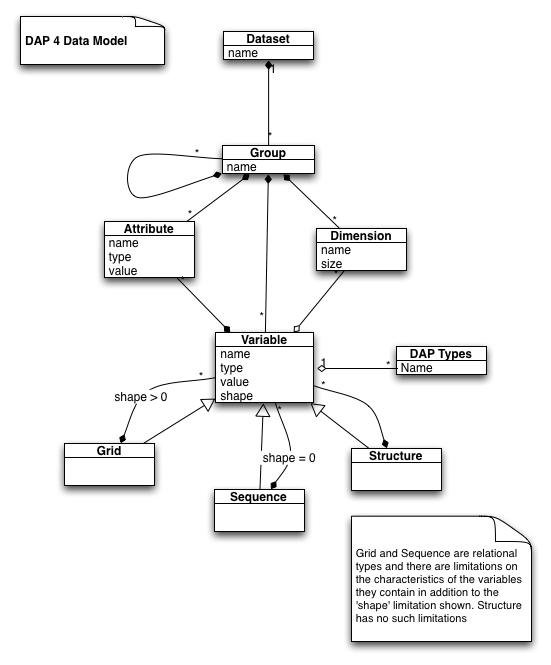
DAP is evolving to meet the increasing complexity of data sources and the improving capabilities of analysis software to act as clients for various online data sources. Part of this evolution is to adopt the Common Data Model that has been developed by Unidata. Other changes are the introduction of new data types and the expansion of capabilities of the widely used 'Grid' type. The Grid type in DAP4 will allow for N-dimensional 'Maps,' multiple 'Array' components and Array components that do not use all of the Maps. Finally, some types like Array of Grid and Array of Sequence have been eliminated because they lack real use-cases and are hard to implement. By eliminating them we hope client authors will focus on complete implementations of the existing types.
The DAP 2 and DAP 4 logical data models are shown to the above, although some details, are skipped. The UML constraint shape indicates if something is an array - shape == 0 means the variable is a scalar while shape > 0 means it has one or more dimensions).
High resolution version of the DAP 2 Data Model High resolution version of the DAP 4 Data Model
{kind=link}
{kind=link}
Dataset
In DAP4, the Dataset object forms the root of the representation of a dataset. In DAP2, this task was split between two different objects, the DDS and DAS, which were also the names of objects used in many implementations. For DAP4, implementations could use the name Dataset. All of the information contained in the data model will be encoded in a 'Dataset response'. In addition, some bookkeeping information might be added to the Dataset response by the server. For a full discussion of the use of the Dataset object in the DAP4 responses please see the DAP4: Responses page.
Data Types
DAP 4 will have a small increase in supported data types. All of the DAP 2 data types describe in ESE RFC 004.11 will be supported with the following exceptions:
- Byte will now indicate a signed 8-bit integer data type (so that UByte can be used to name an unsigned 8-bit integer in keeping with the pattern developed for the *Int?? types).
- Arrays of Grid and Sequence are explicitly excluded from DAP4.
- The Grid type will have some important limitations removed.
- The String type will hold character strings that comply with UTF-8.
- The URL type will comply with the forthcoming IRI RFC.
DAP4 will contain new datatypes that support 64-bit integers, an Opaque type that can be used for data objects like JPEG images, a Group type that can be used to build logical collections as in NetCDF4 or HDF5 (with some limitations over HDF5's definition of Group). In addition, DAP 4 will provide for shared Dimensions and type definitions.
New Datatypes
Groups
The Dataset object must contain one or more Group objects. Like Shared Dimensions and unlike the other types, Group provides a way to form logical associations of variables. Unlike Structure, it cannot itself be used as a component in a constructor type. For example, it is not possible to have an Array of Group while it is certainly possible to have an Array of Structure.
Group characteristics:
- The Group object is similar to the notion of a namespace in a programming languages.
- Each Group declares a new lexical scope for names.
- A Group can contain any object(s), including other Groups.
- All Groups must be named.
- All Groups may have shared Dimensions, which are limited in scope to the enclosing Group.
- All Groups may have DAP Attributes.
- At least one Group must be defined; if a dataset lacks a Group declaration, a Group called root will be defined and all of its variables will be added to that Group.
- A Group cannot be used with a constructor type.
- NB: This definition does not completely subsume the HDF5 Group type but is equivalent to the netCDF 4 version of it. This Group object defines a series of relationships that are purely hierarchical and not a generalized graph (as is the case with the HDF5 Group data model component). Note however, that the URL/IRI type can be used in one Group to reference variables and Dimensions (but not other Groups) defined in another Group.
Shared Dimensions will be added to DAP in the dimensions section of Grid objects. Each shared dimension will consist of a name and a size.
Characteristics of Shared Dimensions:
- Shared Dimensions are not associated with a data type.
- Shared Dimensions do not have DAP attributes.
- Every Shared Dimension has both a name and a size.
- Shared Dimensions are scoped to the Grid that contains them.
- Shared Dimensions are used to define a Map in a Grid.
- Shared Dimensions bind indices in a Map to indices in an Array, forming a linkage between the Array and Map values.
How Group and Dimension differ from other parts of the data model
Both Group and Dimension are used to provide syntactic or structural metadata about a dataset. They do not contain data values themselves. In many cases these objects will not be explicitly represented in the original dataset. Instead, their existence and value(s) will be inferred based on various standards and conventions. The other elements of the data model are used to house data values or semantic metadata read from the dataset (or, in the latter case) synthesized from the values and standards/conventions that the dataset is known to follow.
Opaque
The Opaque type is use to hold objects like JPEG images and other Binary Large Object (BLOB) data that have significant internal structure which might be understood by clients (e.g., an image display program) but that would be very cumbersome to describe using DAP's built-in types. Defining a variable of type 'Opaque' does not communicate any information about its content, although an attribute could be used to do that.
- A variable of type Opaque is treated as a Byte array for the purposes of transmission. This means there is no attempt to re-order four-byte words to or from network byte order and that the block of bytes is extended to fill a four-byte boundary
- The size of an Opaque variable is unknown until the data are read/received
- The Opaque type is a Cardinal Type, which might seem odd because instances of Opaque can be of different sizes. However, comparing similar aspects of Opaque and String indicate that they are Cardinal Types after all.
- NB: Cardinal Types can appear in Group, Array, Structure, Grid and Sequence parts of the data model.
64-bit Integers
Signed and Unsigned 64-bit integers.
Enumeration
When a data source has a variable of type 'Enumeration' a DAP 4 server MUST represent that variable using a integer type, up to an including a 64-bit unsigned integer. However, in practice, these should use Byte variables when transporting the values unless an enumeration contains values too large for that type. This is true because DAP4 will use XDR to encode responses and thus Arrays of Enumerations will encode directly to single byes. If we use other types, like Int16, then they will expand to be 32-bit integers. On the other hand, a single Enumeration will expand to a 32-bit integer for encoding by XDR, but that cost is fairly small.
Variable Length Arrays
Any type that can be an array can have one dimension marked as varying instead of being a fixed size, so long as that dimension is the rightmost dimension.
A Coordinate may not have a dimension that varies; nor may a SharedDimension be varying.
Changes to Existing Types
Changes to index sizes
DAP4 will support Arrays and Grids with 64-bit unsigned indexes.
Signed Bytes
Byte will be a signed 8-bit integer and UByte will be an unsigned 8-bit integer. NB: In DAP2, the Byte data type is defined as an unsigned 8-bit integer and there is no signed 8-bit integer type.
Changes to the String Type
A String is a sequence of characters encoded using UTF-8. Servers MUST translate from local encoding to UTF-8 and client must translate received string data from UTF-8 to any local representation if is not UTF-8. In DAP2, strings were simple C-sytle strings using only ASCII characters.
Changes in the Definition of Grid
In DAP2, the concept of a grid was bound to a datatype that defined its own lexical scope as well as a specific set of operations. In DAP4, the lexical scope has been replaced by a Grid type that 'specializes' the Array type by adding explicit references to one or more Map (aka coordinate variable) variables such that several Grid variables can share one set of Maps. Furthermore, unlike DAP2 the Maps are no longer limited to a rank of one. A Map is also a specialization of an Array.
- General information about Grid:
- A Grid variable is a relational type.
- Dimensions provide the binding between Grid (dependent) and Map (independent) values. The Map value at (i0, i1, ..., in) is bound to the Grid value at the same indicial coordinates when both the Grid and Map use the same shared dimensions for those indices.
- Grids:
- Each Grid variable is an Array-type variable (what is often termed a dependent variable in scientific literature) that has been specialized to include explicit references to one or more Map variables.
- An Grid of rank N may have 1 ... N Maps.
- There is an explicit binding between the Maps and the dimensions of the Grid.
- For an Grid of rank N, all of the Maps referenced by its dimensions must be of rank M <= N.
- Grids may have attributes.
- Maps:
- Maps (often called independent variables) have one or more dimensions.
- Map variables are a restricted class of arrays; only Maps of Byte, ..., Enum are allowed. Maps are a specialization of Array.
- Maps are required to use shared Dimension objects for all of their dimensions.
- Maps may have DAP Attributes.
Examples:
A fairly complex Grid example
This example has four Grids and three Coordinate objects.
How the Coordinates and Grids relate: For any (x,y) value of SST, the latitude and longitude that corresponds to that point can be found from the latitude and longitude Coordinates using those same indices. The Grid indicates that by explicitly sharing the x and y dimensions with those Coordinates using the dimension element's ref attributes and binding the Coordinate to that dimension using the map attribute. For the AirT array, the lat and lon of any (x,y,z) point can be found using (x,y) and the altitude of any point (x,y,z) can be found using the (x,y,z) value of the altitude Coordinate. Again, the shared dimensions provide explicit bindings between the Grid and Coordinate values. Two other examples are shown; no example of a Grid with simple vector coordinates is shown.
<Dimension name="x" size="1024"/>
<Dimension name="y" size="1024"/>
<Dimension name="z" size="12"/>
<!-- The dimensions of a Coordinate MUST be SharedDimensions -->
<Map name="longitude" type="Float32">
<dimension ref="x"/>
<dimension ref="y"/>
</Map>
<Map name="latitude" type="Float32">
<dimension ref="x"/>
<dimension ref="y"/>
</Map>
<Map name="altitude" type="Int32">
<Attribute name="unit" type="String"><value>ft</value></Attribute>
<dimension ref="x"/>
<dimension ref="y"/>
<dimension ref="z"/>
</Map>
<!-- These are the grids... -->
<Byte name="SST">
<dimension ref="x"/>
<dimension ref="y"/>
<map name="latitude"/>
<map name="longitude"/>
</Byte>
<!-- A mixture of two and three-dimensional coordinates -->
<Int16 name="AirT">
<dimension ref="x"/>
<dimension ref="y"/>
<dimension ref="z"/>
<map name="latitude"/>
<map name="longitude"/>
<map name="altitude"/>
</Int16>
<!-- ...some dimensions lack coordinates -->
<Float64 name="intercomparison_result">
<dimension ref="x"/>
<dimension ref="y"/>
<dimension ref="z"/>
<map name="altitude"/>
</Float64>
<!-- ...and in this case the highest dimension coordinate cannot be used to determine the
grid/array rank. -->
<UByte name="model_temperature">
<dimension ref="x"/>
<dimension ref="y"/>
<dimension ref="z"/>
<dimension name="run_number" size="7" />
<map name="latitude"/>
<map name="longitude"/>
<map name="altitude"/>
</UByte>
Types not Included
Discussed in this section are types that are present in some other systems (e.g., ASN 1.1) but that are not explicitly included in DAP 4. For all of these, the information they would encode should be included using attributes. This makes the information available in a way that clients can access if they choose and which people can easily understand without loading up the data model with complexity or optional features. While understanding and reading these attributes is optional for clients, it is required behaviour for conforming servers to encode this information as described here.
Date/Time
When a data source has a variable of type Date, Time or a type that combines those two, a DAP 4 server MUST represent that variable using the String type and include an attribute for that variable named DAP4_Date, DAP4_Time or DAP4_DateTime. The type of the attribute must be String and it must have only one value and that value must indicate how to interpret the date/time value(s) of the variable. As a special case, if the value is ISO-8601 then a client program can assume that the ISO 8601 standard for representation of dates and times is used.
Type definitions
Both HDF5 and NetCDF4 include this as a feature; it is of considerable value for an API that will be used to write data because it provides a way to make a template file with only the data type defined and then have people instantiate those types, resulting in much uniformity. For a data access system, which is read-only, there's less benefit and clients have to be more sophisticated.
DAP4 will not support type definitions (except for Enumerations and SharedDimensions). There is a down side to not supporting the feature, however, and that is that it becomes harder to faithfully represent what's in a data set.
Potential solution:
- Include type definitions in an attribute section - Dataset or Group scope - and then in every Structure that represents a collection of variables with a typedef in the source, include an attribute that names the typedef. This solution frees clients from having to interpret the typedef but savvy clients can reconstruct the original information if needed.
Attributes
In DAP4, Attributes (not to be confused with XML attributes) are tuples with four values:
- Name
- Type
- Vector of values
- Namespace
This differs slightly from DAP2 Attributes because the namespace feature has been added, but clients can choose to ignore it. The intent of including the namespace information is to simplify interactions with semantic web applications where certain formats or standards have formal definitions of attributes (e.g., CF-1.x).
A second difference is that DAP4 explicitly realizes that an attribute with one value is really an attribute whose value is a one-element vector.
Allowed attribute types
The following types are allowed for Attributes:
- All of the Cardinal types except Opaque.
- Arbitrary XML
- Containers (i.e., Structures, but without the capability to be arrays)
As with the String variable type, String Attributes use UTF-8 encoding.
Arbitrary XML content
By supporting an explicit type to hold 'arbitrary XML' markup, DAP4 provides a way for the protocol to transport information encoded in XML along with the attributes read from the dataset itself. This has proved very useful in work with semantic web software.
In an XML representation of DAP4, the name is optional, the XML element is <OtherXML/> and there are no <value/> elements because the 'other xml' appears as the content of the <OtherXML/> element. The value of the attribute must be valid XML and must be distinct from the XML markup used to encode elements of the DAP4 data model (i.e., in a practical sense, the OtherXML must be in a namespace other than DAP4).
Names
Every object in a DAP4 Dataset has a Fully Qualified Name. These names follow the common conventions of lexically-scoped identifiers. To write FQNs, the component names are listed, left to right, corresponding to a traversal of the scopes from outermost to innermost, using dots (.) to separate names associated with lexical scopes. Cases where dots are used in names are accommodated by allowing the names to be quoted and quotes to be escaped using a backslash (\). The (unlikely) sequence "\'" can be represented using "\\'". That is, the backslash can itself be escaped although that is only needed if it is a literal and immediately precedes a literal single quote (').
Objects with FQNs
Each of these Types or Objects has a FQN and some also define a lexical scope:
- Group: A group defines a lexical scope
- SharedDimension
- Map (A Map is a restricted type of an Array)
- Cardinal types
- Arrays
- Types that define lexical scopes:
- Structure
- Sequence
- Grid
Constraint Expressions
In DAP4, Constraint Expressions define the set of operations that the server must support for each data type. These operations are how subsetting and sampling of data are specified and provide the mechanism by which clients indicate which data they want.
The Constraint Expression is encoded as a string and is sent to the server as part of a data request. It is described in the section on Requests and Responses.
Each Constraint Expression (CE) consists of two parts:
- Projection
- Zero or more projection clauses specify what variables are to be included in the response
- Selection
- Zero or more selection clauses are each evaluated for truth and used to determine which values are to be included for the variables named in the projection. The value (true or false) of the selection part is the logical AND of the clauses. Evaluators can stop processing the clauses when the first false value is found. There is no logical OR operation.
The Projection component of the CE is used to:
- Chose which variables are to be retrieved from the dataset
- Which parts of Arrays are to be retrieved, using a 'slicing' concept similar to Python or netCDF3/4 or HDF4/5.
- Which fields of compound types are to be retrieved, using fully qualified names for the fields.
- Call functions that return values
- List several variables and/or functions to retrieve in one operation.
The Selection component of the CE is used to limit the data returned by value:
- For a Cardinal type that is a member of a Sequence, return only those elements of the Sequence that satisfy a set of relational clauses
- For Arrays, return only those elements that satisfy a set of relational clauses. The result of this is a Sequence with N+1 columns for a rank N array; one column for each dimension plus one for the value.
- Functions can be used in place of relational operators
Differences between DAP2 and DAP4 Constraint Expressions
- DAP4 does not support applying array slicing to a Grid. Of course, fields/components of the Grid can be part of the Projection and, since those are arrays, the slicing operator can be used on them.
- An Array may be subset by value using the 'selection' in DAP4
- Functions may appear in both the projection and selection parts of the CE.
- Projection functions compute values that are returned
- Selection functions evaluate to true or false
- DAP2 supported a third kind of function that was used to add 'synthesized' variables to a dataset; those are not included in DAP4 since other techniques can be used to add new variables to a dataset.
Errors
An unsuccessful DAP4 request will cause the server to return a DAP4 error response. The error response may be returned in lieu of the Dataset response, or as part of the Data response. The XML used in the Error response is detailed in the DAP4 schema.
DAP4 Data responses are chunked and DAP4 errors always appear in an error chunk. As the client processes a DAP4 Data response it reads the (fixed length) chunk header prior to reading the chunk. The chunk header will signal to the client that the following chunk contains a DAP4 error object. This enables the client to transition to an error processing state prior to ingesting the error. This is true even when the response contains only an error chunk.
There are 4 types of DAP4 errors.
Internal Error
The error is internal to the Server. Some examples of this are:
- a programming bug/issue.
- out of memory
- disk fail
User Syntax Error
The request contains a syntax error in the selection or the projection clause of the constraint expression. The server should return a message in the error object that explains where in the constraint expression the problem was detected.
Forbidden Error
The requestor is not allowed to access the resource.
I'm starting to think that a Forbidden Error doesn't belong in the DAP4 spec. I think it's the case that in a regular client/server interaction we would expect the authentication/authorization to be handled outside of the DAP4 protocol. If the server is having troubles accessing a resource because of some local/internal issue (like the service is running as a user that isn't allowed to read the resource) then that is starting to sound to me more like an Internal Error. Thoughts?? ndp 12:55, 21 March 2012 (PDT)
Not Found Error
The requested resource cannot be found.