DAP4: Data Model: Difference between revisions
m (moved Data model additions to DAP4: Data Model) |
|||
| Line 4: | Line 4: | ||
: One or more N-dimensional arrays of values bound to 1 to N coordinate variables. In DAP2 the Grid type was limited to one-dimensional coordinate variables; in DAP4 they can be up to N-dimensions. | : One or more N-dimensional arrays of values bound to 1 to N coordinate variables. In DAP2 the Grid type was limited to one-dimensional coordinate variables; in DAP4 they can be up to N-dimensions. | ||
; | ;Cardinal Type | ||
: A data type that cannot be divided using the operators provided by DAP4. The set of | : A data type that cannot be divided using the operators provided by DAP4. The set of Cardinal types are: Byte, Int16, Int32, Int64, their unsigned companions, Float32, Float64, String, URL. Enum (Enumerations) and Opaque. | ||
;Constructor Type | ;Constructor Type | ||
: A data type used to build new structures for representing information. Constructor types gain flexibility by allowing instances of themselves to be elements in a constructed type (i.e., they support recursive definitions). | : A data type used to build new structures for representing information. Constructor types gain flexibility by allowing instances of themselves to be elements in a constructed type (i.e., they support recursive definitions). The ''Structure'', ''Sequence'' and ''Grid'' are the Constructor types in DAP. | ||
;Aggregator Type | ;Aggregator Type | ||
: Arrays and type-homogeneous lists are aggregator types. | : Arrays and type-homogeneous lists are aggregator types. DAP does not contain a List data type since lists can be represented by ''Sequences'' with a single element. | ||
;Variable-size Type | ;Variable-size Type | ||
| Line 18: | Line 18: | ||
;Fixed-size Type | ;Fixed-size Type | ||
: A data type with a fixed size regardless of the value(s) contained. | : A data type with a fixed size regardless of the value(s) contained. | ||
;Dimension | ;Dimension | ||
| Line 30: | Line 27: | ||
;Independent Variable | ;Independent Variable | ||
: A variable included in a data source which is manipulated during measurement or calculation. For example, a ship collecting information about sea temperature might conduct measurements at different latitude and longitudes - the variables used to hold those latitude and longitude values can be described as ''independent variables.'' The term has its origin in Mathematics and Statistics, each of which have subtly different definitions, but in the context of a data source the independent variables are often once that might be encoded as attributes and not variables except for the fact that the values of an independent variable are often larger in volume (KB to MB) and users of the data often need to select a subset of the values, an operation that is often not supported for attributes. | : A variable included in a data source which is manipulated during measurement or calculation. For example, a ship collecting information about sea temperature might conduct measurements at different latitude and longitudes - the variables used to hold those latitude and longitude values can be described as ''independent variables.'' The term has its origin in Mathematics and Statistics, each of which have subtly different definitions, but in the context of a data source the independent variables are often once that might be encoded as attributes and not variables except for the fact that the values of an independent variable are often larger in volume (KB to MB) and users of the data often need to select a subset of the values, an operation that is often not supported for attributes. | ||
;Coordinate Variable | |||
: A Coordinate Variable is the binding of a Shared Dimension to a data type so that the values of an independent variable may be stored in a data source and their relation to a dependent variable made explicit. The Grid data type is used by DAP4 to define coordinate variables, which it names ''Map''s. | |||
;Dependent Variable | ;Dependent Variable | ||
Revision as of 18:20, 14 February 2012
Definitions
- Grid
- One or more N-dimensional arrays of values bound to 1 to N coordinate variables. In DAP2 the Grid type was limited to one-dimensional coordinate variables; in DAP4 they can be up to N-dimensions.
- Cardinal Type
- A data type that cannot be divided using the operators provided by DAP4. The set of Cardinal types are: Byte, Int16, Int32, Int64, their unsigned companions, Float32, Float64, String, URL. Enum (Enumerations) and Opaque.
- Constructor Type
- A data type used to build new structures for representing information. Constructor types gain flexibility by allowing instances of themselves to be elements in a constructed type (i.e., they support recursive definitions). The Structure, Sequence and Grid are the Constructor types in DAP.
- Aggregator Type
- Arrays and type-homogeneous lists are aggregator types. DAP does not contain a List data type since lists can be represented by Sequences with a single element.
- Variable-size Type
- A data type that does not define a fixed number of bits/bytes for its network representation. Examples of these types are Strings, Opaques and Sequences. Note that an Array or Structure containing instances of Opaque defines a variable-size type even though an Array or Structure that contains only, say, Int32 variables, defines a Fixed-size Type.
- Fixed-size Type
- A data type with a fixed size regardless of the value(s) contained.
- Dimension
- The term dimension is used in some places as a short form for Shared Dimension, defined below.
- Shared Dimension
- A Shared Dimension is the binding of a name to a integer. The name can then be used in place of the integer to indicate the extent of a variable with one or more dimensions. Using a Shared Dimension to describe the extent of two or more array variables describes the way that parts of the variables are related.
- Independent Variable
- A variable included in a data source which is manipulated during measurement or calculation. For example, a ship collecting information about sea temperature might conduct measurements at different latitude and longitudes - the variables used to hold those latitude and longitude values can be described as independent variables. The term has its origin in Mathematics and Statistics, each of which have subtly different definitions, but in the context of a data source the independent variables are often once that might be encoded as attributes and not variables except for the fact that the values of an independent variable are often larger in volume (KB to MB) and users of the data often need to select a subset of the values, an operation that is often not supported for attributes.
- Coordinate Variable
- A Coordinate Variable is the binding of a Shared Dimension to a data type so that the values of an independent variable may be stored in a data source and their relation to a dependent variable made explicit. The Grid data type is used by DAP4 to define coordinate variables, which it names Maps.
- Dependent Variable
- A variable included in a data source which is measured or calculated as a function of independent variables. For example, if a data source held demographic information about cities' populations and median income levels, the data about income levels would be a dependent variable. As with the term independent variable, this term has its origin in Mathematics and statistics.
Data Model


DAP is evolving to meet the increasing complexity of data sources and the improving capabilities of analysis software to act as clients for various online data sources. Part of this evolution is to adopt the Common Data Model that has been developed by Unidata. Other changes are the introduction of new data types and the expansion of capabilities of the widely used 'Grid' type. The Grid type in DAP4 will allow for N-dimensional 'Maps,' multiple 'Array' components and Array components that do not use all of the Maps. Finally, some types like Array of Grid and Array of Sequence have been eliminated because they lack real use-cases and are hard to implement. By eliminating them we hope client authors will focus on complete implementations of the existing types.
The DAP 2 and DAP 4 data models are shown to the above, although some details, are skipped. The UML constraint shape indicates if something is an array - shape == 0 means the variable is a scalar while shape > 0 means it has one or more dimensions).
High resolution version of the DAP 2 Data Model High resolution version of the DAP 4 Data Model
{kind=link}
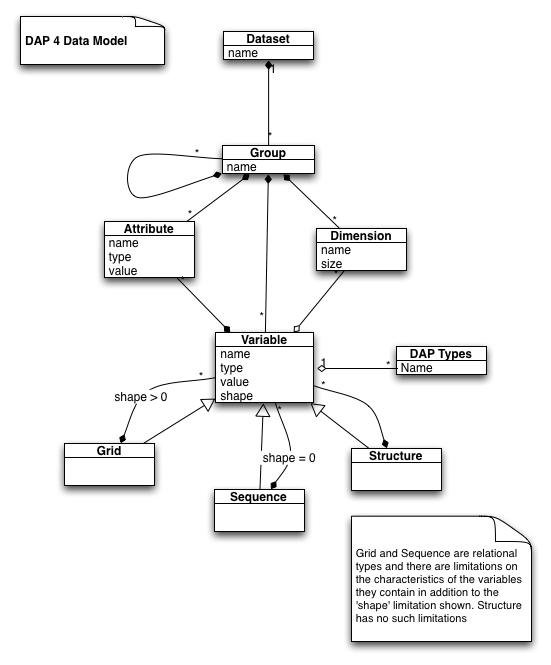{kind=link}
Dataset
In DAP4, the Dataset object forms the root of the representation of a dataset. In DAP2, this task was split between two different objects, the DDS and DAS, which were also the names of objects used in many implementations. For DAP4, implementations could use the name Dataset. All of the information contained in the data model will be encoded in a 'Dataset response' although we might use the older name DDX in place of Dataset. In addition, some bookkeeping information might be added to the Dataset/DDX response.
The format(s) that the DAP4 responses can take on will be discussed elsewhere.
Data Types
DAP 4 will have a small increase in supported data types. All of the DAP 2 data types describe in ESE RFC 004.11 will be supported with their existing definition with the exceptions that Grid will be expanded so that it can be used in more situations and strings will comply with UTF-8. The additional types will support 64-bit integers, an Opaque type that can be used for data objects like JPEG images, Groups that can be used to build logical collections as in NetCDF4 or HDF5 (with some limitations over HDF5's definition of Group). In addition, DAP 4 will provide for Shared Dimensions and Type Definitions. Both Shared Dimensions and Type Definitions will allow data systems that have these to be presented with better fidelity than DAP 2.
New Datatypes
Groups
The Dataset object must contain one or more Group objects.
Group characteristics:
- The Group object is similar to the notion of a namespace in a programming languages
- Each Group declares a new lexical scope for values.
- A Group can contain any object, including a Group
- All Groups must be named.
- All Groups may have Shared dimensions, which are limited in scope to the enclosing Group.
- At least one Group must be defined; if a dataset lacks a Group declaration, a Group called root will be defined and all of its variables will be added to that Group.
- A Group cannot be an Array, Grid, Structure or Sequence. That is, it is certainly possible to have a Group that contains Arrays, Grids, et c., but it is not possible to have an Array of Groups.
- This definition does not completely subsume the HDF5 Group type but is equivalent to the netCDF 4 version of it. This Group object defines a series of relationships that are purely hierarchical and not a generalized graph (as is the case with the HDF5 Group data model component).
Shared dimensions (or just Dimension) will be added to DAP in the dimensions section of Group objects. Each Dimension will consist of a name and a size.
<Dimension name="lat" size="1024"/>
<Dimension name="lon" size="1024"/>
Characteristics of Dimensions:
- Dimensions are not associated with a data type.
- Dimensions do not have attributes.
- Every Dimension has both a name and a size.
- Dimensions may be used by both Grids and Arrays.
- Dimensions bound to a type define Maps.
- A Map is not restricted to to being a single dimension; a N-dimensional coordinate variable would use N dimensions.
How Group and Dimension differ from other parts of the data model
Both Group and Dimension are used to provide syntactic or structural metadata about a dataset. They do not contain data values themselves. In many cases these objects will not be explicitly represented in the original dataset. Instead, their existence and value(s) will be inferred based on various standards and conventions. The other elements of the data model are used to house data values or semantic metadata read from the dataset (or, in the latter case) synthesized from the values and standards/conventions that the dataset is known to follow.
Opaque
The Opaque type is use to hold objects like JPEG images and other BLOB objects with significant internal structure that might be understood by some clients (e.g., an image display program) but which would be very cumbersome to describe using DAP's built-in types. Defining a variable of type 'Opaque' does not communicate any information about its content, although an attribute could be used to do that.
- A variable of type Opaque is treated as a Byte array for the purposes of transmission. This means there is no attempt to re-order four-byte words to or from network byte order and that the block of bytes is extended to fill a four-byte boundary
- The size of an Opaque variable is unknown until the data are read/received
- The Opaque type should be considered similar to a 'simple type' in that it can appear in a Structure.
- It's possible to have Arrays of Opaque variables
- It's possible to have Sequences that contain Opaque variables
Questions:
- Grid of Opaque items?
- Because of the complexity of dealing with variable length items, should a client be allowed (they'd still be consider fully compliant clients) to not read Opaque variables?
Signed Bytes
Byte will be a signed 8-bit integer and UByte will be an unsigned 8-bit integer. NB: In DAP2, the Byte data type is defined as an unsigned 8-bit integer and there is no signed 8-bit integer type.
64-bit Integers
Signed and Unsigned 64-bit integers.
Enumeration
When a data source has a variable of type 'Enumeration' a DAP 4 server MUST represent that variable using a integer type, up to an including a 64-bit unsigned integer. However, in practice, these should use Byte variables when transporting the values unless an enumeration contains values too large for that type. This is true because DAP4 will use XDR to encode responses and thus Arrays of Enumerations will encode directly to single byes. If we use other types, like Int16, then they will expand to be 32-bit integers. On the other hand, a single Enumeration will expand to a 32-bit integer for encoding by XDR, but that cost is fairly small.
Changes to Existing Types
Changes to index sizes
DAP4 will support Arrays and Grids with 64-bit unsigned indexes.
Changes in the Definition of Grid
While dimensions are scoped at the Dataset or Group level, coordinate variables are defined at the level of a Grid object. Grid objects in DAP4 are different from those in DAP2 in three ways beyond using (shared) dimensions:
- A Grid object is a relational type that is similar to a map in C++ or Java in that it provides a way to relate values held in an array to non-index values such as Strings or (more commonly in scientific data) floating point values.
- Each Grid has zero or more Dimension objects, one or more Maps and one or More Arrays.
- Maps provide the mapping between the non-index values and the indicial coordinates of the Array (i.e., There is an explicit relation between the Grid object's Maps and the indicial extents of the Grid's Arrays).
- Each Grid object defines a lexical scope.
Array:
- Each Grid object may hold more than one Array (what is often termed a dependent variable in scientific literature)
- In an Grid's Array object, <Map...> elements are used to specify the array's dimensions; the word dimension is avoided to cut down on confusion.
- The dimensionality of the Array (or maximum dimensionality of the union of the Arrays) determines the maximum dimensionality of the Maps
- There may be some Arrays that do not use all of the Maps
Map:
- Each Array within a Grid is not constrained to use all of the Grid's Maps
- Maps (often called independent variables) may have more than one dimension
- The Map object may have the same name as a Dimension object
- Map objects may have attributes, even though they are not shown in the examples below
- Maps are not required to use Dimension objects for all of their dimensions (they may use sizes instead).
- Map in this context is equivalent to netCDF's use of the term Coordinate variable.
Dimension:
- There may be Dimensions that are unused
NB: In DAP2, there was a mapping (one to one and onto) between the Maps and Array such that the number of Map vectors had to match the number of dimensions in the Array. In DAP4, this is no longer true, although there are still limitations.
Questions:
- One problem with Grid in DAP4 is that if a Grid contains more than one Array, we'd have to settle on exactly what <grig_name>[0:10][0:20] means. Does it mean return the Grid such that all of its child arrays have been sampled according to [0:10][0:20]?
- What about the case where some child Arrays don't have all of the dimensions? Should we just apply the constraints that can be applied and ignore the extras?
One approach for the case when Maps are not simple vectors: When using the [] operator on a Grid in a DAP Constraint expression, the arguments enclosed in the square brackets correspond to the dimensions declared in the Grid and not the Maps themselves. Thus a CE like SST_Swath[10:20][40:50] means that the array SST_Swath.SST and the maps SST_Swath.longitude and SST_Swath.latitude will all be returned sub-sampled to elements 10 to 20 in their first dimension and 40 to 50 in their second. In a DAP2 grid where all of the maps are vectors, there is a one-to-one correspondence between the [] operators and Maps, but in a DAP4 Grid there is a one-to-one correspondence between the [] operators and dimensions. In simple cases like the DAP 2 Grids, the dimension and map names should be the same.
Examples:
A very simple Grid object
<Dataset name="example_1">
<!-- Note that capitalized elements are part of the data model, while lower-case elements encode aspects of those data model components -->
<Dimension name="lon" size="1024"/>
<Dimension name="lat" size="1024"/>
<Grid>
<Map name="lon" type="Float32">
<dim name="lon"/>
</Map>
<Map name="lat" type="Float32">
<dim name="lat"/>
</Map>
<Array name="SST">
<type>
<Byte/>
</type>
<Map name="lon">
<Map name="lat">
</Array>
</Grid>
</Dataset>
A more complex Grid object
<Dataset>
<Dimension name="pt" size="4096">
<Dimension name="span" size="128">
<Grid>
<Map name="longitude" type="Float32">
<dim name="pt"/>
</Map>
<Map name="latitude" type="Float32">
<dim name="pt"/>
</Map>
<Map name="altitude" type="Float32">
<dim name="pt"/>
</Map>
<Map name="time" type="Float32">
<dim name="span"/>
</Map>
<!-- Here's a Map that does not use a Dimension -->
<Map name="counts" type="Uint64">
<dim size="1024"/>
</Map>
<Array name="Radioactivity">
<< attributes >> <!-- for example, scale_factor and add_offset -->
<type>
<Byte/>
</type>
<Map name="longitude"/>
<Map name="latitude"/>
<Map name="altitude"/>
<Map name="time"/>
</Array>
<Array name="surface_temp">
<< attributes >>
<type>
<Float64/>
</type>
<Map name="longitude"/>
<Map name="latitude"/>
<Map name="time"/>
</Array>
</Grid>
</Dataset>
An example Grid with Maps that are not vectors
<Dataset>
<Dimension name="x" size="4096">
<Dimension name="y" size="4096">
<Grid name="SST_Swath">
<!-- We could list multiple dims in a space-separated list
but purists will gag. I'm experimenting with different
syntaxes -->
<Map name="longitude" type="Float32">
<dim name="x"/>
<dim name="y"/>
</Map>
<Map name="latitude" type="Float32">
<dim name="x"/>
<dim name="y"/>
</Map>
<!-- This grid has two maps, each of which are two-dimensional
arrays. It can be used to store satellite 'swath' data. -->
<Array name="SST">
<< attributes >> <!-- for example, scale_factor and add_offset -->
<type>
<Byte/>
</type>
<Map name="longitude"/>
<Map name="latitude"/>
</Array>
</Grid>
</Dataset>
Changes to the Array Type
Arrays will support the use of Dimensions.
Changes to the String Type
In DAP 2, the String type was essentially a clone of the C language string conventions combined with XDR's encoding of those character arrays. In DAP 4 a String is a sequence of characters encoded using UTF-8. Servers MUST translate from local encoding to UTF-8 and client must translate received string data from UTF-8 to any local representation if is not UTF-8.
NB: String is a variable-length type.
Types not Included
Discussed in this section are types that are present in some other systems (e.g., ASN 1.1) but that are not explicitly included in DAP 4. For all of these, the information they would encode should be included using attributes. This makes the information available in a way that clients can access if they choose and which people can easily understand without loading up the data model with complexity or optional features. While understanding and reading these attributes is optional for clients, it is required behaviour for conforming servers to encode this information as described here.
Date/Time
When a data source has a variable of type Date, Time or a type that combines those two, a DAP 4 server MUST represent that variable using the String type and include an attribute for that variable named DAP4_Date, DAP4_Time or DAP4_DateTime. The type of the attribute must be String and it must have only one value and that value must indicate how to interpret the date/time value(s) of the variable. As a special case, if the value is ISO-8601 then a client program can assume that the ISO 8601 standard for representation of dates and times is used.
Type definitions
We can support these two ways: DAP4 can expand the types in place (the current behavior) or; it can include a typedef (which is technically a data type synonym) and use that name throughout the remainder of the DDX.
Both HDF5 and NetCDF4 include this as a feature; it is of considerable value for an API that will be used to write data because it provides a way to make a template file with only the data type defined and then have people instantiate those types, resulting in much uniformity. For a data access system, which is read-only, there's very little benefit. What's more, clients have to be more sophisticated.
There is a down side to not supporting the feature, however, and that is that it becomes harder to faithfully represent what's in a data set. This might be important if some semantics are bound to the fact that a data set has a particular type defined. That the type has been included might of value in and of itself.
Potential solution:
- Include type definitions in an attribute section that's global - Dataset or Group scope - and then in every Structure that represents a collection of variables with a typedef in the source, include an attribute that names that typedef. This way clients don't have to interpret the typedef but a savvy client can reconstruct the original information if needed.
Attributes
Attributes in DAP 4 are largely unchanged from DAP 2 with the only changes being
- The addition of a new type of attribute to hold XML which is supplied for a data source using some external system.
- Some new integer types (wider word sizes)
- Enumerations
- The addition of an optional namespace for each attribute.
- Consider moving all attributes to the variable space and tagging them. This deals with How do you deal with attributes in a constrained response? because only the stuff asked for is returned when constrained.
- Alternate solution to this question attributes in the constrained response: Don't return the DDX in the data response but use a multipart MIME where each part holds one variable (as defined by the Checksum feature) and prefixed with a data type declaration. The entire response could be prefixed with a xml:base href to the DDX/Dataset URL.
Note: jimg: I think we need to set a 'special' top-level container that can hold extra information that clients can use. We've wound up doing this in the past to accommodate short falls in the DAP2 spec and it seems optimistic to assume we won't ever need it with DAP4
Existing Attribute Types
The existing attribute types of DAP 2 are unchanged in DAP 4. These types are Byte, Int16, Int32, UInt16, UInt32, Float32, Float64, String and URL. Each my be either scalar or vector. Also provided by DAP 2 is a constructor type that is synonymous with Structure but is used with attributes to create groupings and lexical scopes.
Changes to the existing attribute types
String and URL attributes in DAP 4 use the UTF-8 encoding.
New Attribute Types
64-bit Integers, both signed and unsigned
Signed Byte
The Byte type will become a signed byte in DAP4 and unsigned bytes will be represented using UByte.
Enumerations
Like the integral types, this is pretty straightforward.
XML
In the DAP 3.3 schema these attributes, which are actually xsd:any elements, are not represented using <Attribute type-"OtherXML" ...> but are instead represented using a new element type called <AnyXML name="..."> since this can be described using schema 1.0. In practice these should be considered DAP attributes with a value that is the text of the XML.
The <AnyXML> element must have a name attribute. It may have any other attributes. The content is not restricted to any particular namespace and the processing is set to lax meaning that its content will be validated only if the XML elements are defined, otherwise they will not be validated.
Even though the name is klunky, OtherXML has served us well. Do we really need to change?