DAP 4.0 Design: Difference between revisions
| Line 36: | Line 36: | ||
== New Datatypes == | == New Datatypes == | ||
=== Groups === | === Groups === | ||
Revision as of 18:14, 4 June 2009
This is a Draft
Introduction
Overall Operation
Definitions
- Type Definition
- The representation of something in a data set which defines a data type; types are defined in a data set. The DAP provides a way to represent this definition and use it as a stand-in for a definition built using the DAP-supplied types.
- Dimension
- A name bound to a size, e.g., "lon" has a size of 1024
- Coordinate Variable
- A name bound to both a dimension and a data type, e.g.,"height" is a vector of dimension "height_size" 32-bit floating point numbers, or "latitude" is an array of dimension "x" by dimension "y" 32-bit floating point numbers.
- Grid
- One or more N-dimensional arrays of values bound to 1 to N coordinate variables.
Data Model


DAP is evolving to meet the increasing complexity of data sources and the improving capabilities of analysis software to act as clients for various online data sources. Part of this evolution is to adopt the Common Data Model that has been developed by Unidata and other changes are the introduction of new data types and the expansion of capabilities of the widely used 'Grid' type. Finally, some types like Array of Grid and Array of Sequence have been eliminated because they lack real use-cases and are hard to implement. By eliminating them we hope client authors will focus on complete implementations of the existing types.
The DAP 2 and DAP 4 data models are shown to the above.
High resolution version of the DAP 2 Data Model High resolution version of the DAP 4 Data Model
{kind=link}
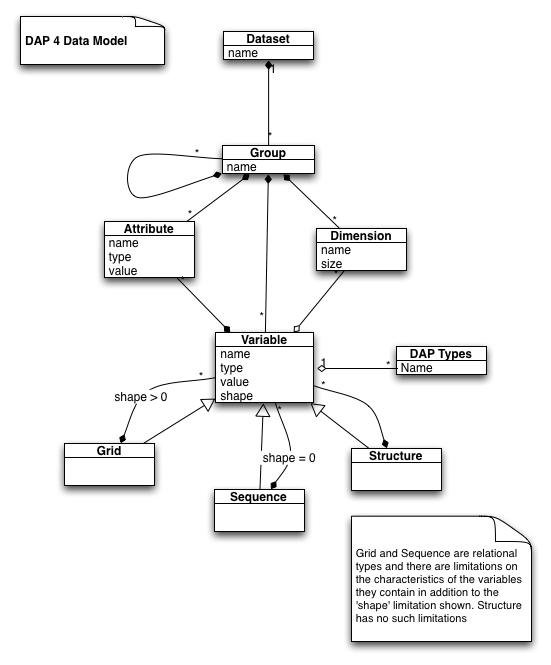{kind=link}
Data Types
DAP 4 will have a small increase in supported data types. All of the DAP 2 data types describes in ESE RFC 004.11 will be supported with their existing definition with the exceptions that Grid will be expanded so that it can be used in more situations and strings will comply with UTF-8. The additional types will support 64-bit integers, an Opaque type that can be used for data objects like JPEG images, Groups that can be used to build logical collections as in NetCDF4 or HDF5 (with some limitations over HDF5's definition of Group). In addition, the server-side of DAP 4 will provide for Shared Dimensions and Type Definitions. Both Shared Dimensions and Type Definitions will allow data systems that have these to be presented with better fidelity than DAP 2.
New Datatypes
Groups
The DDX will be modified so that it contains one or more Groups. If only one Group is present (which describes the case for DAP 3.2 and earlier) then the declaration can be left out, but if there are two or more groups, the declarations must be present.
Group characteristics:
- Any configuration of Groups other than one (anonymous) Group which holds all the variables in a data set must be declared.
- If declared, Groups must be named.
- A Group can contain any object, including a Group
- Variables and Attributes are named using / <group name> / ... / <variable name> to reflect their hierarchy.
- Each Group declares a new lexical scope for values.
- A Group cannot be an Array or a Grid (although the distinction between those two might become blurred or non-existent; Group is fundamentally a scalar container-type).
- This definition does not completely subsume the HDF5 Group type but is equivalent to the netCDF 4 version of it.
Shared dimensions will be added to DAP in the dimensions section of the Dataset or Group objects. Each dimension will consist of a name and a size.
<dimension name="lat" size="1024"/> <dimension name="lon" size="1024"/>
Characteristics of dimensions:
- Dimensions are not associated with a data type.
- Dimensions do not have attributes.
- Dimensions bound to a type define coordinate variables.
- Shared dimensions may be used by both Grids and Arrays.
- A Coordinate variable is not restricted to to being a single dimension; a N-dimensional coordinate variable would use N dimensions.
From an email exchange, John Caron wrote:
James:
Is it that an dimension is a formal declaration of an independent parameter?
John:
I know that some people prefer that interpretation. My own opinion is that's it more complicated.
Abstractly, I think its reasonable to say that the number of dimensions of a variable indicates its dimensionality in the topological sense. I think its necessary to allow "independent variables" to have topological dimensionality > 1. eg lat(x,y), lon(x,y). lat and lon can still be considered independent variables, but they are not orthogonal. Neither is associated exclusively with one
dimension.
Concretely, dimensions are used for all sorts of reasons, and are not just about topological dimensionality. For instance, they control the grouping of data and the layout of files. So in real files, you see this mixture of uses.
That's why the explicit assignment of coord variables is needed, which makes your Grid attractive, because that's a way of explicitly saying what the independent variables are. One needs shared dimensions between data and coordinate variables, so that one can unambiguously assign coordinate values to a data value.
The downsides of using Grid for this purpose:
- the name "Grid" connotes gridded data, eg model data, and this shared dimension thing is needed for other types of data, eg point data.
- If Grid scopes the dimension, then all variables sharing a dimension have to be contained in the grid. So its impossible to have some dimensions globally shared, and others locally shared.
So my preference would be to use Groups to scope shared dimensions, rather than Grids. But still use Grids (or some evolution of Grids) to assign coordinate variables to data variables.
Opaque
The Opaque type is use to hold objects like JPEG images and other BLOB objects with significant internal structure that might be understood by some clients (e.g., an image display program) but which would be very cumbersome to describe using DAP's built-in types. Defining a variable of type 'Opaque' does not communicate any information about its content, although an attribute could be used to do that.
- A variable of type Opaque is treated as a Byte array for the purposes of transmission. This means there is no attempt to re-order four-byte words to or from network byte order and that the block of bytes is extended to fill a four-byte boundary
- The size of an Opaque variable is unknown until the data are read/received
- The Opaque type should be considered similar to a 'simple type' in that it can appear in a Structure.
- It's possible to have Arrays of Opaque variables
Questions:
- Does it make sense to have a Grid of Opaque items?
- Opaques in a Sequence?
- Because of the complexity of dealing with variable length items, should a client be allowed (they'd still be consider fully compliant clients) to not read Opaque variables?
64-bit Integers
Signed and Unsigned 64-bit integers.
Support for Existing Types
Changes in the Definition of Grid
While dimensions are scoped at the Dataset or Group level, coordinate variables are defined at the level of a Grid object. Grid objects in DAP4 are different from those in DAP2 in three ways beyond using (shared) dimensions:
- Each Grid object may hold more than one Array (what is often a dependent variable);
- Maps (often independent variables) may have more than one dimension; and
- Each Array within a Grid is not constrained to use all of the Grid's Maps (aka coordinate variables).
N.B: Coordinate variables in a Grid object are called Maps to conform to the old nomenclature and to avoid (re)using the word dimension.
Features of the DAP4 and DAP2 Grid object:
- Each Grid object defines a lexical scope.
- There is an explicit relation between the Grid object's maps (coordinate variables) and the indicial extents of the array.
A very simple Grid object
<dataset name="example_1">
<dimension name="lon" size="1024"/>
<dimension name="lat" size="1024"/>
<grid>
<map name="lon" dim="lon" type="Float32"/>
<map name="lat" dim="lat" type="Float32"/>
<array name="SST">
<Byte/>
<map name="lon">
<map name="lat">
</array>
</grid>
</dataset>
Notes:
- The map object may have the same name as a dimension object.
- Map objects may have attributes, even though they are not shown in the example.
- In an Grid's array object, <map...> elements are used to specify the array's dimensions; the word dimension is avoided to cut down on confusion.
A more complex Grid object
<dataset>
<dimension name="pt" size="4096">
<dimension name="span" size="128">
<grid>
<map name="longitude" dim="pt" type="Float32"/>
<map name="latitude" dim="pt" type="Float32"/>
<map name="altitude" dim="pt" type="Float32"/>
<map name="time" dim="span" type="Float32">
<< attributes >> <!-- The syntax for attributes is in flux -->
</map>
<array name="Radioactivity">
<< attributes >> <!-- for example, scale_factor and add_offset -->
<Byte/>
<map name="longitude"/>
<map name="latitude"/>
<map name="altitude"/>
<map name="time"/>
</array>
<array name="surface_temp">
<< attributes >>
<float64/>
<map name="longitude"/>
<map name="latitude"/>
<map name="time"/>
</array>
</grid>
</dataset>
An example Grid with Maps that are not vectors
<dataset>
<dimension name="x" size="4096">
<dimension name="y" size="4096">
<grid name="SST_Swath">
<!-- We could list multiple dims in a space-separated list
but purists will gag. I'm experimenting with different
syntaxes -->
<map name="longitude" type="Float32"/>
<dim name="x"/>
<dim name="y"/>
</map>
<map name="latitude" type="Float32"/>
<dim name="x"/>
<dim name="y"/>
</map>
<!-- This grid has two maps, each of which are two-dimensional
arrays. It can be used to store satellite 'swath' data. -->
<array name="SST">
<< attributes >> <!-- for example, scale_factor and add_offset -->
<Byte/>
<map name="longitude"/>
<map name="latitude"/>
</array>
</grid>
</dataset>
Note:
- The highest dimension of the Grid's Maps cannot exceed the dimensionality of the Grid's Array.
- When using the [] operator on a Grid in a DAP Constraint expression, the arguments enclosed in the square brackets correspond to the dimensions declared in the Map and not the Maps themselves. Thus a CE like SST_Swath[10:20][40:50] means that the array SST_Swath.SST and the maps SST_Swath.longitude and SST_Swath.latitude will all be returned sub-sampled to elements 10 to 20 in their first dimension and 40 to 50 in their second. In a DAP2 grid where all of the maps are vectors, there is a one-to-one correspondence between the [] operators and Maps, but in a DAP4 Grid there is a one-to-one correspondence between the [] operators and dimensions. In simple cases like the DAP 2 Grids, the dimension and map names should be the same.
Changes to the String Type
Suggested Types not Included
Discussed in this section are types that are present in some other systems (e.g., ASN 1.1) but that are not explicitly included in DAP 4. For all of these, the information they would encode should be included using attributes. This makes the information available in a way that clients can access if they choose and which people can easily understand without loading up the data model with complexity or optional features. While understanding and reading these attributes is optional for clients, it is required behaviour for conforming servers to encode this information as described here.
Enumeration
When a data source has a variable of type 'Enumeration' a DAP 4 server MUST represent that variable using a integer type and include an attribute for that variable named DAP4_Enumeration. The type of the attribute MUST be string and the values will be alternately an integer value and the corresponding symbolic name.
Both HDF5 ad NetCDF4 contain Enumerations and other data sources may contain equivalent types. If a type is clearly an enumeration, then the server MUST encode it as described above. If the variable appears to be an enumeration even though the data source does not explicitly include that type or use it in a particular instance, it MAY be encoded as described here but server writers should know that certain clients may treat the variable as if it is really a formally defined Enumeration. To avoid this behaviour, don't use the attribute name DAP4_Enumeration.
DAP4 Clients should be careful about assuming that a variable that looks like an enumeration is in fact one unless the DAP4_Enumeration attribute is present.
Boolean
When a data source has a variable of type 'Boolean' a DAP 4 server MUST represent that variable using an integer type and include an attribute for that variable named DAP4_Boolean. The type of the attribute MUST be String and MUST include four values: The integer value that represents 'true'; the string true, True or TRUE; the integer value that represents false; and the string false, False or FALSE.
In essence DAP 4 treats the boolean type in a data source as it treats an enumeration and all of the other conditions regarding enumerations hold for boolean types.
Date/Time
When a data source has a variable of type Date, Time or a type that combines those two, a DAP 4 server MUST represent that variable using the String type and include an attribute for that variable named DAP4_Date, DAP4_Time or DAP4_DateTime. The type of the attribute must be String and it must have only one value and that value must indicate how to interpret the date/time value(s) of the variable. As a special case, if the value is ISO-8601 then a client program can assume that the ISO 8601 standard for representation of dates and times is used.
What does CF use for this? Days since ...? Alternative: Look at the UD Units package and document those representations.
Type definitions
When a data source contains one or more type definitions (i.e., type equivalents) that will be used throughout the remainder of the data source to denote the type of variables, a DAP 4 server MUST create an attribute at the same lexical scope level as the type definition named DAP4_Typedef. The attribute MUST be of type String and must consist of two values for each type definition: The name of the type as given in the data source; and the value, expressed using DAP4 types using the XML notation detailed in this document.
Attributes
Attributes in DAP 4 are largely unchanged from DAP 2 with the only change being the addition of a new type of attribute to hold XML which is supplied for a data source using some external system.
Existing Attribute Types
New Attribute Types
XML
Names
Services
We need to add some 'discovery' services so that a client can find out about different handlers and the customizations they support. One form of service discovery would be to return the server-side functions present on the server in a way that would lead to a client being able to ask for more information about each one, with the intent that a person could use this or that an interface could be built around this information (choose the function from a list). A second service would be to learn about installed handlers so that a client could then ask for information about a specific one. For example, a client might ask about handlers, see that a HDF5 handler is present and then ask for documentation on it. That would reveal that the handler encodes type definitions in global attributes - information that would be useful if you're trying to write a HDF5 file and want high fidelity.
The problem with services like this is that they can be a real pain if server installers have to write it up. These services need to be returning information that is part of the handler or function. Then the server interagates the handler or function and builds up the information. So the server installer does not have to write this stuff up.
Examples
Responses
Persistent representations
DDX Document Organization
DAP and the DDX will be extended to include Groups, Shared dimensions and user-defined types. Groups will be added as a kind of constructor-type with properties similar to Structure and to Java or C++ namespaces. Unlike Structure, Groups cannot be dimensioned.
A rough syntax which describes how these additions will fit into the DAP and the existing DDX Notation is (Replace with XML schema):
Dataset :== Groups Groups :== null | Group Groups Group :== Types Dimensions Attributes Variables Groups Types :== null | Type Types Dimensions :== null | Dimension Dimensions Attributes :== null | Attribute Attributes Variables :== null | Variable Variables
This pseudo-grammar does not capture what can be produced for a Group, et cetera. Instead it shows how these sections of the DDX must be organized. It also does not show that a valid Dataset can have only Types (user-define types) and does not need to have variables, but it must have one or the other or both.
Examples
Group Examples
This data set contains one Group - the root group - which has by convention the name '/'
<Dataset ... >
...
</Dataset>
This data set contains two Groups, one after the other.
<Dataset ... >
<group name="primary">
...
</group>
<group name="secondary">
...
</group>
</Dataset>
This data set contains more Groups, and shows they can be nested.
<Dataset ... >
<group name="primary">
...
<group name="in_situ">
...
</group>
</group>
<group name="secondary">
...
</group>
</Dataset>