DAP 4.0 Design
Draft
Introduction
Instead of splitting the doc up into a Model and Theory section followed by an Implementation section, split up each topic into Model & Theory and then include the relevant XML so that the data model is made concrete right from the start.
DAP4 is fundamentally a data access protocol that consists of a data model and request/response semantics. However, to ground the DAP4 design and frame it in a context that is immediately useful, this document includes information about the implementation of a web service that implements the protocol. In a later version of the document, the web service aspects of the DAP4 may be moved to a separate document. In all of the design, HTTP headers may be used to encode information, but they are not the only way that information can be accessed. For example, DAP4 responses return version information and it makes sense to incude that in the HTTP response headers. This same information will be included in the response document body too, so that other transport protocols can be used with DAP4.
Definitions
- Grid
- One or more N-dimensional arrays of values bound to 1 to N coordinate variables. In DAP2 the Grid type was limited to one-dimensional coordinate variables; in DAP4 they can be up to N-dimensions.
- Atomic Type
- A data type that cannot be divided using the operators provided by DAP4. The set of Atomic types are: Byte, Int16, Int32, Int64, their unsigned companions, Float32, Float64, String, URL.
Are Opaque and Enumeration also atomic types? Should they be allowed in all of the same contexts as the others (e.g., a Grid of Opaques)?
- Constructor Type
- A data type used to build new structures for representing information. Constructor types gain flexibility by allowing instances of themselves to be elements in a constructed type (i.e., they support recursive definitions).
- Aggregator Type
- Arrays and type-homogeneous lists are aggregator types.
- Variable-size Type
- A data type that does not define a fixed number of bits/bytes for its network representation. Examples of these types are Strings, Opaques and Sequences. Note that an Array or Structure containing instances of Opaque defines a variable-size type even though an Array or Structure that contains only, say, Int32 variables, defines a Fixed-size Type.
- Fixed-size Type
- A data type with a fixed size regardless of the value(s) contained.
- Coordinate Variable
- A Coordinate Variable is the binding of a Shared Dimension to a data type so that the values of an independent variable may be stored in a data source and their relation to a dependent variable made explicit. The Grid data type is used by DAP4 to define coordinate variables.
- Dimension
- The term dimension is used in some places as a short form for Shared Dimension, defined below.
- Shared Dimension
- A Shared Dimension is the binding of a name to a integer. The name can then be used in place of the integer to indicate the extent of a variable with one or more dimensions. Using a Shared Dimension to describe the extent of two or more array variables describes the way that parts of the variables are related.
- Independent Variable
- A variable included in a data source which is manipulated during measurement or calculation. For example, a ship collecting information about sea temperature might conduct measurements at different latitude and longitudes - the variables used to hold those latitude and longitude values can be described as independent variables. The term has its origin in Mathematics and Statistics, each of which have subtly different definitions, but in the context of a data source the independent variables are often once that might be encoded as attributes and not variables except for the fact that the values of an independent variable are often larger in volume (KB to MB) and users of the data often need to select a subset of the values, an operation that is often not supported for attributes.
- Dependent Variable
- A variable included in a data source which is measured or calculated as a function of independent variables. For example, if a data source held demographic information about cities' populations and median income levels, the data about income levels would be a dependent variable. As with the term independent variable, this term has its origin in Mathematics and statistics.
Data Model


DAP is evolving to meet the increasing complexity of data sources and the improving capabilities of analysis software to act as clients for various online data sources. Part of this evolution is to adopt the Common Data Model that has been developed by Unidata. Other changes are the introduction of new data types and the expansion of capabilities of the widely used 'Grid' type. The Grid type in DAP4 will allow for N-dimensional 'Maps,' multiple 'Array' components and Array components that do not use all of the Maps. Finally, some types like Array of Grid and Array of Sequence have been eliminated because they lack real use-cases and are hard to implement. By eliminating them we hope client authors will focus on complete implementations of the existing types. DAP4 will also support the concepts of REST more explicitly by including, initially in the protocol, a response that provides links to all of the other response types defined in/by the protocol.
The DAP 2 and DAP 4 data models are shown to the above.
High resolution version of the DAP 2 Data Model High resolution version of the DAP 4 Data Model
{kind=link}
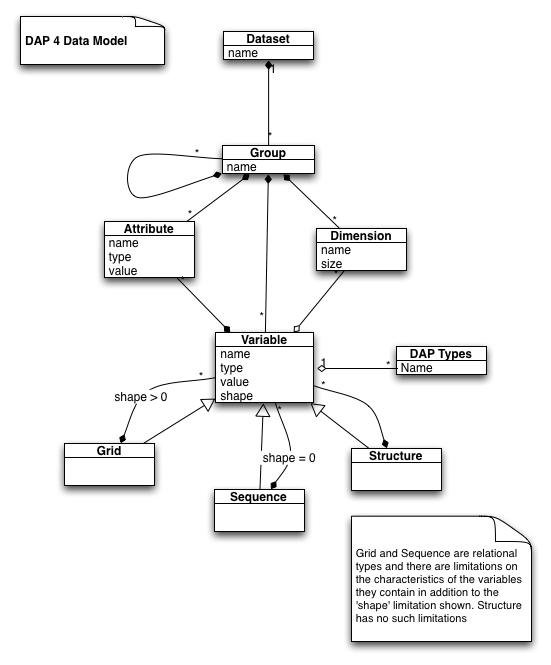{kind=link}
Data Types
DAP 4 will have a small increase in supported data types. All of the DAP 2 data types describe in ESE RFC 004.11 will be supported with their existing definition with the exceptions that Grid will be expanded so that it can be used in more situations and strings will comply with UTF-8. The additional types will support 64-bit integers, an Opaque type that can be used for data objects like JPEG images, Groups that can be used to build logical collections as in NetCDF4 or HDF5 (with some limitations over HDF5's definition of Group). In addition, the server-side of DAP 4 will provide for Shared Dimensions and Type Definitions. Both Shared Dimensions and Type Definitions will allow data systems that have these to be presented with better fidelity than DAP 2.
New Datatypes
Groups
The DDX will be modified so that it contains one or more Groups. If only one Group is present (which describes the case for DAP 3.2 and earlier) then the declaration can be left out, but if there are two or more groups, the declarations must be present.
Group characteristics:
- Any configuration of Groups other than one (anonymous) Group which holds all the variables in a data set must be declared.
- If declared, Groups must be named.
- A Group can contain any object, including a Group
Variables and Attributes are named using / <group name> / ... / <variable name> to reflect their hierarchy.(removed because the syntax makes the membership explicit given Group's purely hierarchical nature).- Each Group declares a new lexical scope for values.
- A Group cannot be an Array, Grid, Structure or Sequence. That is, a Group cannot used with type aggregators (Array) or type constructors (Structure) or relational types (Sequence, Grid)
- This definition does not completely subsume the HDF5 Group type but is equivalent to the netCDF 4 version of it.
Shared dimensions will be added to DAP in the dimensions section of the Dataset or Group objects. Each dimension will consist of a name and a size.
<dimension name="lat" size="1024"/> <dimension name="lon" size="1024"/>
Characteristics of dimensions:
- Dimensions are not associated with a data type.
- Dimensions do not have attributes.
- Dimensions bound to a type define coordinate variables.
- Shared dimensions may be used by both Grids and Arrays.
- A Coordinate variable is not restricted to to being a single dimension; a N-dimensional coordinate variable would use N dimensions.
Opaque
The Opaque type is use to hold objects like JPEG images and other BLOB objects with significant internal structure that might be understood by some clients (e.g., an image display program) but which would be very cumbersome to describe using DAP's built-in types. Defining a variable of type 'Opaque' does not communicate any information about its content, although an attribute could be used to do that.
- A variable of type Opaque is treated as a Byte array for the purposes of transmission. This means there is no attempt to re-order four-byte words to or from network byte order and that the block of bytes is extended to fill a four-byte boundary
- The size of an Opaque variable is unknown until the data are read/received
- The Opaque type should be considered similar to a 'simple type' in that it can appear in a Structure.
- It's possible to have Arrays of Opaque variables
Questions:
- Does it make sense to have a Grid of Opaque items?
- Opaques in a Sequence?
- Because of the complexity of dealing with variable length items, should a client be allowed (they'd still be consider fully compliant clients) to not read Opaque variables?
Signed Bytes
In DAP2, the Byte data type is defined as an unsigned 8-bit integer. In DAP4 we will introduce a SByte type to accommodate a signed byte data type.
64-bit Integers
Signed and Unsigned 64-bit integers.
Enumeration
When a data source has a variable of type 'Enumeration' a DAP 4 server MUST represent that variable using a integer type. Because Enumerations is netCDF4 (and probably HDF5) can be any size integer up to 64-bit unsigned, we will adopt that as well. When the we will bind a 'representation type' to the variable in the DAP 4 DDX.
Changes to Existing Types
Changes to index sizes
DAP4 will support Arrays and Grids with 64-bit unsigned indexes.
Changes in the Definition of Grid
While dimensions are scoped at the Dataset or Group level, coordinate variables are defined at the level of a Grid object. Grid objects in DAP4 are different from those in DAP2 in three ways beyond using (shared) dimensions:
- Each Grid object may hold more than one Array (what is often a dependent variable);
- Maps (often independent variables) may have more than one dimension; and
- Each Array within a Grid is not constrained to use all of the Grid's Maps (aka coordinate variables).
N.B: Coordinate variables in a Grid object are called Maps to conform to the old nomenclature.
Features of the DAP4 and DAP2 Grid object:
- Each Grid object defines a lexical scope.
- There is an explicit relation between the Grid object's maps (coordinate variables) and the indicial extents of the array.
A very simple Grid object
<dataset name="example_1">
<dimension name="lon" size="1024"/>
<dimension name="lat" size="1024"/>
<grid>
<map name="lon" dim="lon" type="Float32"/>
<map name="lat" dim="lat" type="Float32"/>
<array name="SST">
<Byte/>
<map name="lon">
<map name="lat">
</array>
</grid>
</dataset>
Notes:
- The map object may have the same name as a dimension object.
- Map objects may have attributes, even though they are not shown in the example.
- In an Grid's array object, <map...> elements are used to specify the array's dimensions; the word dimension is avoided to cut down on confusion.
A more complex Grid object
<dataset>
<dimension name="pt" size="4096">
<dimension name="span" size="128">
<grid>
<map name="longitude" dim="pt" type="Float32"/>
<map name="latitude" dim="pt" type="Float32"/>
<map name="altitude" dim="pt" type="Float32"/>
<map name="time" dim="span" type="Float32">
<< attributes >> <!-- The syntax for attributes is in flux -->
</map>
<array name="Radioactivity">
<< attributes >> <!-- for example, scale_factor and add_offset -->
<Byte/>
<map name="longitude"/>
<map name="latitude"/>
<map name="altitude"/>
<map name="time"/>
</array>
<array name="surface_temp">
<< attributes >>
<float64/>
<map name="longitude"/>
<map name="latitude"/>
<map name="time"/>
</array>
</grid>
</dataset>
An example Grid with Maps that are not vectors
<dataset>
<dimension name="x" size="4096">
<dimension name="y" size="4096">
<grid name="SST_Swath">
<!-- We could list multiple dims in a space-separated list
but purists will gag. I'm experimenting with different
syntaxes -->
<map name="longitude" type="Float32"/>
<dim name="x"/>
<dim name="y"/>
</map>
<map name="latitude" type="Float32"/>
<dim name="x"/>
<dim name="y"/>
</map>
<!-- This grid has two maps, each of which are two-dimensional
arrays. It can be used to store satellite 'swath' data. -->
<array name="SST">
<< attributes >> <!-- for example, scale_factor and add_offset -->
<Byte/>
<map name="longitude"/>
<map name="latitude"/>
</array>
</grid>
</dataset>
Note:
- The highest dimension of the Grid's Maps cannot exceed the dimensionality of the Grid's Array.
- When using the [] operator on a Grid in a DAP Constraint expression, the arguments enclosed in the square brackets correspond to the dimensions declared in the Map and not the Maps themselves. Thus a CE like SST_Swath[10:20][40:50] means that the array SST_Swath.SST and the maps SST_Swath.longitude and SST_Swath.latitude will all be returned sub-sampled to elements 10 to 20 in their first dimension and 40 to 50 in their second. In a DAP2 grid where all of the maps are vectors, there is a one-to-one correspondence between the [] operators and Maps, but in a DAP4 Grid there is a one-to-one correspondence between the [] operators and dimensions. In simple cases like the DAP 2 Grids, the dimension and map names should be the same.
Problems with Grid in DAP4
One problem with Grid in DAP4 is that if a Grid contains more than one Array, we'd have to settle on exactly what <grig_name>[0:10][0:20] means. Does it mean return the Grid such that all of its child arrays have been sampled according to [0:10][0:20]? What about the case where some child Arrays don't have all of the dimensions? Should we just apply the constraints that can be applied and ignore the extras?
Alternative to DAP4's Grid
We could use the combination of Group and Shared Dimensions to represent Grid. Here are the three preceding examples reworked to use this new notation:
A very simple Grid object
<dataset name="example_1">
<group name="SST">
<dimension name="lon" size="1024"/>
<dimension name="lat" size="1024"/>
<array name="lon" dim="lon"><Float64/></array>
<array name="lat" dim="lat"/><Float64/></array>
<array name="SST">
<Byte/>
<map name="lon">
<map name="lat">
</array>
</group>
</dataset>
Notes:
- The map object may have the same name as a dimension object.
- Map objects may have attributes, even though they are not shown in the example.
- In an Grid's array object, <map...> elements are used to specify the array's dimensions; the word dimension is avoided to cut down on confusion.
A more complex Grid object
<dataset>
<dimension name="pt" size="4096">
<dimension name="span" size="128">
<grid>
<map name="longitude" dim="pt" type="Float32"/>
<map name="latitude" dim="pt" type="Float32"/>
<map name="altitude" dim="pt" type="Float32"/>
<map name="time" dim="span" type="Float32">
<< attributes >> <!-- The syntax for attributes is in flux -->
</map>
<array name="Radioactivity">
<< attributes >> <!-- for example, scale_factor and add_offset -->
<Byte/>
<map name="longitude"/>
<map name="latitude"/>
<map name="altitude"/>
<map name="time"/>
</array>
<array name="surface_temp">
<< attributes >>
<float64/>
<map name="longitude"/>
<map name="latitude"/>
<map name="time"/>
</array>
</grid>
</dataset>
An example Grid with Maps that are not vectors
<dataset>
<dimension name="x" size="4096">
<dimension name="y" size="4096">
<grid name="SST_Swath">
<!-- We could list multiple dims in a space-separated list
but purists will gag. I'm experimenting with different
syntaxes -->
<map name="longitude" type="Float32"/>
<dim name="x"/>
<dim name="y"/>
</map>
<map name="latitude" type="Float32"/>
<dim name="x"/>
<dim name="y"/>
</map>
<!-- This grid has two maps, each of which are two-dimensional
arrays. It can be used to store satellite 'swath' data. -->
<array name="SST">
<< attributes >> <!-- for example, scale_factor and add_offset -->
<Byte/>
<map name="longitude"/>
<map name="latitude"/>
</array>
</grid>
</dataset>
Changes to the Array Type
Arrays will support the use of Shared Dimensions.
Changes to the String Type
In DAP 2, the String type was essentially a clone of the C language string conventions combined with XDR's encoding of those character arrays. In DAP 4 a String is a sequence of characters encoded using UTF-8. Servers MUST translate from local encoding to UTF-8 and client must translate received string data from UTF-8 to any local representation if is not UTF-8.
NB: String is a variable-length type.
Types not Included
Discussed in this section are types that are present in some other systems (e.g., ASN 1.1) but that are not explicitly included in DAP 4. For all of these, the information they would encode should be included using attributes. This makes the information available in a way that clients can access if they choose and which people can easily understand without loading up the data model with complexity or optional features. While understanding and reading these attributes is optional for clients, it is required behaviour for conforming servers to encode this information as described here.
Date/Time
When a data source has a variable of type Date, Time or a type that combines those two, a DAP 4 server MUST represent that variable using the String type and include an attribute for that variable named DAP4_Date, DAP4_Time or DAP4_DateTime. The type of the attribute must be String and it must have only one value and that value must indicate how to interpret the date/time value(s) of the variable. As a special case, if the value is ISO-8601 then a client program can assume that the ISO 8601 standard for representation of dates and times is used.
Type definitions
We can support these two ways: DAP4 can expand the types in place (the current behavior) or; it can include a typedef (which is technically a data type synonym) and use that name throughout the remainder of the DDX.
Both HDF5 and NetCDF4 include this as a feature; it is of considerable value for an API that will be used to write data because it provides a way to make a template file with only the data type defined and then have people instantiate those types, resulting in much uniformity. For a data access system, which is read-only, there's very little benefit. What's more, clients have to be more sophisticated.
There is a down side to not supporting the feature, however, and that is that it becomes harder to faithfully represent what's in a data set. This might be important if some semantics are bound to the fact that a data set has a particular type defined. That the type has been included might of value in and of itself.
Attributes
Attributes in DAP 4 are largely unchanged from DAP 2 with the only changes being
- The addition of a new type of attribute to hold XML which is supplied for a data source using some external system.
- Some new integer types (wider word sizes)
- Enumerations
- The addition of an optional namespace for each attribute.
Note: jimg: I think we need to set a 'special' top-level container that can hold extra information that clients can use. We've wound up doing this in the past to accommodate short falls in the DAP2 spec and it seems optimistic to assume we won't ever need it with DAP4
Existing Attribute Types
The existing attribute types of DAP 2 are unchanged in DAP 4. These types are Byte, Int16, Int32, UInt16, UInt32, Float32, Float64, String and URL. Each my be either scalar or vector. Also provided by DAP 2 is a constructor type that is synonymous with Structure but is used with attributes to create groupings and lexical scopes.
Changes to the existing attribute types
String and URL attributes in DAP 4 use the UTF-8 encoding.
New Attribute Types
64-bit Integers, both signed and unsigned
Unsigned Bytes
Enumerations
Like the integral types, this is pretty straightforward.
XML
In the DAP 3.3 schema these attributes, which are actually xsd:any elements, are not represented using <Attribute type-"OtherXML" ...> but are instead represented using a new element type called <AnyXML name="..."> since this can be described using schema 1.0. In practice these should be considered DAP attributes with a value that is the text of the XML.
The <AnyXML> element must have a name attribute. It may have any other attributes. The content is not restricted to any particular namespace and the processing is set to lax meaning that its content will be validated only if the XML elements are defined, otherwise they will not be validated.
Even though the name is klunky, OtherXML has served us well. Do we really need to change?
Names
Here we define the allowable characters in an identifier. There are two or three kind of identifiers:
- Variable names
- Attribute names
- typedefs (if we include them)
Note that the names of DAP4 types are fixed and won't ever include characters like '%'.
Services
We need to add some 'discovery' services so that a client can find out about different handlers and the customizations they support. One form of service discovery would be to return the server-side functions present on the server in a way that would lead to a client being able to ask for more information about each one, with the intent that a person could use this or that an interface could be built around this information (choose the function from a list). A second service would be to learn about installed handlers so that a client could then ask for information about a specific one. For example, a client might ask about handlers, see that a HDF5 handler is present and then ask for documentation on it. That would reveal that the handler encodes type definitions in global attributes - information that would be useful if you're trying to write a HDF5 file and want high fidelity.
The problem with services like this is that they can be a real pain if server installers have to write it up. These services need to be returning information that is part of the handler or function. Then the server interagates the handler or function and builds up the information. So the server installer does not have to write this stuff up.
This should move the HTTP binding document
Requests
DAP4 makes the division between itself and its implementation as a web service more distinct than DAP2. Here we present the form of requests independent of HTTP and the Web.
A request for a DAP4 response object must include a pathname that describes the subject of that request. DAP4 supports two response objects: DDX and DataDDX. The DDX contains all of the available metadata for a data set; the DataDDX combines an abbreviated view of metadata bound to a binary data payload. Both of these objects may be modified by a contrant expression. The intent of these two response types is that a client will ask for a DDX to find out about a data set and a DataDDX to get data it contains.
Asking for a DDX
When asking for a DAP4 DDX, the requestor must supply a pathname and may optionally supply a constraint expression.
Asking for a DataDDX
When asking for the DataDDX, the requestor must supply a pathname and may optionally supply a constraint expression. It may also ask for a checksum to be computed for the data response.
Version
This is a way for the new version of the protocol to incorporate protocol version negotiation. There are two ways that clients can request that a server respond suing a specific version of the protocol.
- Using a HTTP Resquest header
- Using a keyword prefixed to the projection part of the CE
Using a header to request a specific DAP version
XDAP-Accept
Only one x.y value is allowed. Other syntax will be ignored and multiple values have undefined behavior.
Only works with HTTP/Web services.
Using keywords
A set of tokens will be defined; zero of one of which may appear before any variables (but after other keywords if more keywords are added). The token will identify a specific version of the protocol.
Precedence
A keyword takes precedence over the XDAP-Accept header which takes precedence over the server's default.
Server response
The server will signal the version of the DAP it is using for the response using both the XDAP header (for HTTP responses) and by including the version in the DDX object included with the response.
Server requirements
Servers SHOULD honor the clients request, but MAY choose to respond with a lower version. Server MUST not respond with a higher version of the protocol.
Servers that cannot respond with a version <= the client's request should return an Error.
Responses
Persistent representations
DAP4 defines only two response objects*: The DDX and DataDDX. Since the later includes the DDX, that XML document is common to all/both DAP4 responses. In DAP2, important information was present only in the HTTP headers. In DAP4, all of the information specified by the protocol will be present in the DDX document. Some of that information may also be present in HTTP headers, for example, when it's appropriate. Other protocols might have other ideas about where information like where the particular DAP version should go and the DAP binding for that protocol will include that information. But regardless, the DDX itself will be a standalone document.
All character data is assumed to be UTF8 encoded.
*But see the DAP4 Web Services document for the list of response objects - both required and suggested.
DDX Organization
DAP4 and the DDX will be extended to include Groups, Shared dimensions and user-defined types. Groups will be added as a kind of constructor-type with properties similar to Structure and to Java or C++ namespaces. Unlike Structure, Groups cannot be dimensioned.
A rough syntax which describes how these additions will fit into the DAP and the existing DDX Notation is (Replace with XML schema):
Dataset :== Groups | anonymous_group anonymous_group :== Dimensions Attributes Groups Variables Groups :== null | Group Groups Group :== Dimensions Attributes Groups Variables Dimensions :== null | Dimension Dimensions Attributes :== null | Attribute Attributes Variables :== null | Variable Variables
This pseudo-grammar does not capture what can be produced for a Group, et cetera. Instead it shows how these sections of the DDX must be organized.
NB: If a DDX describes a data set that has been constrained, attributes will not be included. It is not possible to know if attributes correctly describe the data once it has been constrained.
Elements
Dataset
The Dataset element is the root element of the DDX response.
The Dataset element has the following attributes:
- name
- The name of the dataset. This can be any name the server chooses. This should probably be the name of the file or database table/token.
- dapVersion
- The version of DAP used by the server to form this DDX. This must be in digit dot digit form (e.g., "3.2") Why not dap:version?
- xml:base
- The value of the xml:base attribute is the URL which was dereferenced to get this DDX. The xml namespace should also be declared in the Dataset element.
How much of the other namespaces and attributes (e.g., grddl:transformation) need to be formally part of the DAP4 specification?
Here's and example of the Dataset element:
<Dataset name="fnoc1.nc" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xml.opendap.org/ns/DAP/3.2# http://xml.opendap.org/dap/dap/3.2.xsd" xmlns:grddl="http://www.w3.org/2003/g/data-view#" grddl:transformation="http://xml.opendap.org/transforms/ddxToRdfTriples.xsl" xmlns="http://xml.opendap.org/ns/DAP/3.2#" xmlns:dap="http://xml.opendap.org/ns/DAP/3.2#" dapVersion="3.2" xmlns:xml="http://www.w3.org/XML/1998/namespace" xml:base="http://test.opendap.org/opendap/data/nc/fnoc1.nc.ddx" >
Examples
Group Examples
This data set contains one Group - the root group - which has by convention the name '/'
<Dataset ... >
...
</Dataset>
This data set contains two Groups, one after the other.
<Dataset ... >
<group name="primary">
...
</group>
<group name="secondary">
...
</group>
</Dataset>
This data set contains more Groups, and shows they can be nested.
<Dataset ... >
<group name="primary">
...
<group name="in_situ">
...
</group>
</group>
<group name="secondary">
...
</group>
</Dataset>
DataDDX Organization
NB: There's also a page just on the DDX, including links to information about chunking: DataDDX
A DataDDX response is the way DAP4 returns data to a client. Each DataDDX response is returned over the wire as a multipart MIME document where the first part contains the DDX describing the data requested and the second part contains the data values, encoded using XDR. Some aspects of this design have been borrowed from the W3C's "SOAP Messages with Attachments" and the OGC's "WCS Version 1.1 Corrigendum 2" specifications. See also The MIME Multipart/Related Content-type (rfc 2387) and MIME part one.
In DAP2 the 'data' or 'DataDDS' response is a MIME document with Content-Type 'application/octet-stream' which means essentially that the contents of the MIME document are binary and application specific, in this case specific to applications the understand DAP2. Within that dcoument, the DDS is used to provide the syntax needed to decode the binary information. Following the DDS is a separator and following that are data values written to the document using XDR.
The use of XDR is solely to ensure that the data values can be read on both little- and big-endian machines and that floating-point values do not suffer from the many different representations commonly found. In additon, XDR is used to onclude information about the size of arrays, string ans URLs, the latter two of which are really special case arry types. Thus XDR provides a common encoding for the bits and bytes to be transferred. It does not. however, represent any of the more complex structural information such as the organization of relational data.
The DDS sent with the DataDDS response is used to describe the organization of the data not covered by XDR. For example, if the response calls for values from three variables to be returned, the DDS in the DataDDS response will list those three variables and, furthermore, do so in the order that their values appear in the response. The variables described in the DDS response match exactly in number, type, shape and order with the data in the 'data part' of the response.
The DataDDX follows the basic design of DAP2's DataDDS response closely. The DDX included describes the number, type, shape and order of each variable with values in the binary part of the response. However, while the DAP2 response used a simple application/octet-stream document, DAP4 uses a multipart MIME document. The design of this document/response can accommodate including including several different data requests in one document, a feature useful for implementations of DAP that do not use HTTP for transport.
Transmitting Attributes in the DDX contained in the DataDDX Response
The DDX contained in the DataDDX Response will not contain any Attribute nodes.
Since the contents of the DataDDX are the result of access to the data subject to a constraint, various aspects of any of th variables in the response may have been changed. To make these changes the DAP must take into account the semantics of each of the variables' data types. It can do this because the semantics for the types are well defined and known a priori. However, this is not the case for attributes, where the semantics are intentionally not part of the DAP. The DAP is merely an 'envelope' for the name-type-value tuples of the attributes.
To understand why this restriction is placed on the DDX returned in the DataDDX response, lets examine a common example. Suppose an image has some extent and has attributes that name that extent. A geographical image might have attributes that provide the latitude and longitude of two opposite corners and a medial image might have attributes that provide the height and width in millimeters. Now suppose the image is constrained in one or more dimensions, how should the attribute values be treated? If they are left alone they are likely no longer correct but to modify them requires detailed information about how they map to the image and while this information might be know to a client that has an understanding of a particular subject area, expecting the server to handle them correctly would require it to know about every subject area for all of the data to be served.
An alternative to 'universal knowledge' is to allow servers to return attributes that have 'well known' semantics and drop other attributes. While this is appealing at first, it presents a complex situation to clients because to make use of the attributes in the return DataDDX response they must know to test for them and if not present, fallback to some default behavior. In our opinion, it is easier to present clients with fewer 'optional behaviors', especially when the fallback is likely to compute the needed value anyway.
Organization of the multipart MIME document
Here's what the shell of the document looks like:
Content-Type: multipart/related; type="text/xml"; start="<<start id>>"; boundary="<<boundary>>" --<<boundary>> Content-Type: text/xml; charset=UTF-8 Content-Transfer-Encoding: binary Content-Id: <<start id>> Content-Description: ddx <<DDX here. This includes a reference to <<data id>> >> --<<boundary>> Content-Type: application/octet-stream Content-Transfer-Encoding: binary Content-Id: <<data id>> Content-Description: data <<XDR encoded binary data>> --<<boundary>>
The example shows three sets of MIME headers separated by two --<<boundary>> lines; a third boundary line terminates the document. The first group of headers (in a real response, there would be other headers here like Date, XDAP, and others) provide information need to recognize the boundary separators and to find the first part of the document by matching the value of start to a Content-Id of one of the parts. The payload of that first part contains references to the related parts using the values of their Content-Id headers.
The DDX will reference the data part using an XML element with the name blob. The blob element will have an attribute href that will contain the value of the data part's Content-Id headers (<> in the example above). Be sure to read the information about Adding the Data element. NB: The existing code for DAP3.2 does not use this. Instead it implements the <blob> element described here.
- Could this be an entry point to a really easy mechanism for asynchronous (delayed) responses?
- This might be implemented by altering the dap:blob element (or element). Currently we propose using an href attribute to hold the content ID for the MIME part that holds the data:
<dap:blob href="cid:someUUID" />
- We might consider allowing an alternate representation:
<dap:blob
xlink:href="http://the.server/location/where/you/can/get/the/binary/part"
xlink:type="simple"
available="TimeItWillBeAvailableInSomeISOFormat"
/>
- That would indicate to the user that the content will be available asynchronously.
--ndp 12:42, 30 March 2010 (PDT)
Roberto's suggestion regarding HTTP headers
This succinct suggestion for adding support to asynchronous responses came from Roberto De Almeida (roberto at dealmeida.net):
My suggestion would be to return a 202 Accepted (http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html#sec10.2.3) response with a "Location:" header pointing to a unique URL. Accessing the new URL should return either a 404 Not found if the response is not ready; 200 OK if it is; and 410 Gone if it has been generated and deleted after some time.
Comment: jimg 18:47, 22 January 2009 (PST) This effectively factors the issue out of DAP; how asynchronous behavior will be handled is dependent on the transport protocol. I think that's essentially correct. For example, SOAP has an asynchronous mode and DAP over SOAP should use that, not some DAP-specific hack.
Resolution
As with the protocol resolution, I think that it's best to combine the two techniques. We should modify the (or <blob>) element so that it can indicate that the response has to be obtained from somewhere else and/or at a later time. But we should also leverage HTTP and use the 202/404/410 response codes and Location: header.
Choosing values for the DataDDX Content-Ids and Boundaries
We would like the software that builds these DataDDX responses to be compatible with as many different transport protocols as possible, so long as the cost to the implementation for which we know we must support is low. One thing that some transport protocols may do is combine several DataDDX responses into a single document and, while the specifics of that will vary between protocols, one choice we can make now that will facilitate that is to ensure that the values of the Content-Ids and <<boundary>>s are unique within and across systems. This will free software that combines DataDDX responses from having to process the DDX and Content-Id header to ensure that no name collisions are present. While using UUIDs, for example, makes the result values 'ugly', it adds virtually nothing to the time needed to build or process the responses. Other schemes, that combine a URI with some system-generated token could also be employed. The important point is to ensure that these symbols are unique not only within a system, but across systems.
Changes to the encoding of data
There are some issues with the way data values are encoded in DAP2 that we can address now.
- Arrays are prefixed with their sizes, the total number of elements, twice in DAP 2 because of an initial misuse of the xdr library. Now is the time to fix that and have just one copy of the Array size in DAP 4.
- Sequences are encoded in a way that's optimal but which requires fairly complex Constraint expression evaluation. We can reduce the likelihood that servers fail to implement the Selection sub-expression evaluation by simplifying it a bit.
- We can embed tags in the binary data to make it easier to read.
Appendices
DDX Schema
In the DDX, DAP Array objects are represented like so:
<Array name="chlor">
<Byte/>
<dimension name="time" size="46"/>
<dimension name="lat" size="2160"/>
<dimension name="lon" size="4320"/>
</Array>
The problem is that the array template is identified simply by it's presence and position in the document. While this is representable in XML schema, it turns out to be problematic for clients that wish to process the content. Thus, the template variable should be wrapped in a <template> tag as a way of making it's relationship ship to the Array element explicit:
<Array name="chlor">
<template/>
<Byte/>
</template>
<dim name="time" size="46"/>
<dim name="lat" size="2160"/>
<dim name="lon" size="4320"/>
</Array>
The schema needs to be updated to reflect this change in the implementation.
Note that in DAP4 the <dimension ...> element is used to represent an abstract dimension object that can be shared by several variables. So we're left with the task of finding a good name for 'the dimensions of an array'. Here I used <dim ...> but there should be a better name. Or not...